基于机器学习的IC电子产品数据挖掘
最近获取到了一份IC电子产品电商数据的分析,后面会进行3个主题的数据分析:
- 第一阶段:基于pandas、numpy、matplotlib、plotly等库的统计可视化分析
- 第二阶段:基于机器学习聚类算法和RFM模型的用户画像分析
- 第三阶段:基于关联规则算法的品牌、产品和产品种类关联性挖掘
本文是第一个阶段,主要内容包含:
- 数据预处理
- 数据探索EDA
- 多角度对比分析
导入库
In [1]:
1 | import pandas as pd |
数据基本信息
读取数据
1 | df = pd.read_csv( |
基本信息
In [3]:
1 | # 1、数据shape |
Out[3]:
1 | (564169, 11) |
In [4]:
1 |
|
Out[4]:
1 | event_time object |
In [5]:
1 | # 3、数据描述统计信息 |
Out[5]:
| price | age | |
|---|---|---|
| count | 564169.000000 | 564169.000000 |
| mean | 208.269324 | 33.184388 |
| std | 304.559875 | 10.122088 |
| min | 0.000000 | 16.000000 |
| 25% | 23.130000 | 24.000000 |
| 50% | 87.940000 | 33.000000 |
| 75% | 277.750000 | 42.000000 |
| max | 18328.680000 | 50.000000 |
In [6]:
1 | # 4、总共多少个不同客户 |
Out[6]:
1 | 6908 |
In [7]:
1 | # 5、总共多少个不同品牌 |
Out[7]:
1 | 868 |
In [8]:
1 | # 6、总共多少个订单 |
Out[8]:
1 | 234232 |
In [9]:
1 | # 7、总共多少个产品 |
Out[9]:
1 | 3756 |
数据预处理
数据筛选
从描述统计信息中发现price字段的最小值是0,判定位异常;我们选择price大于0的信息:
In [10]:
1 | df = df[df["price"] > 0] |
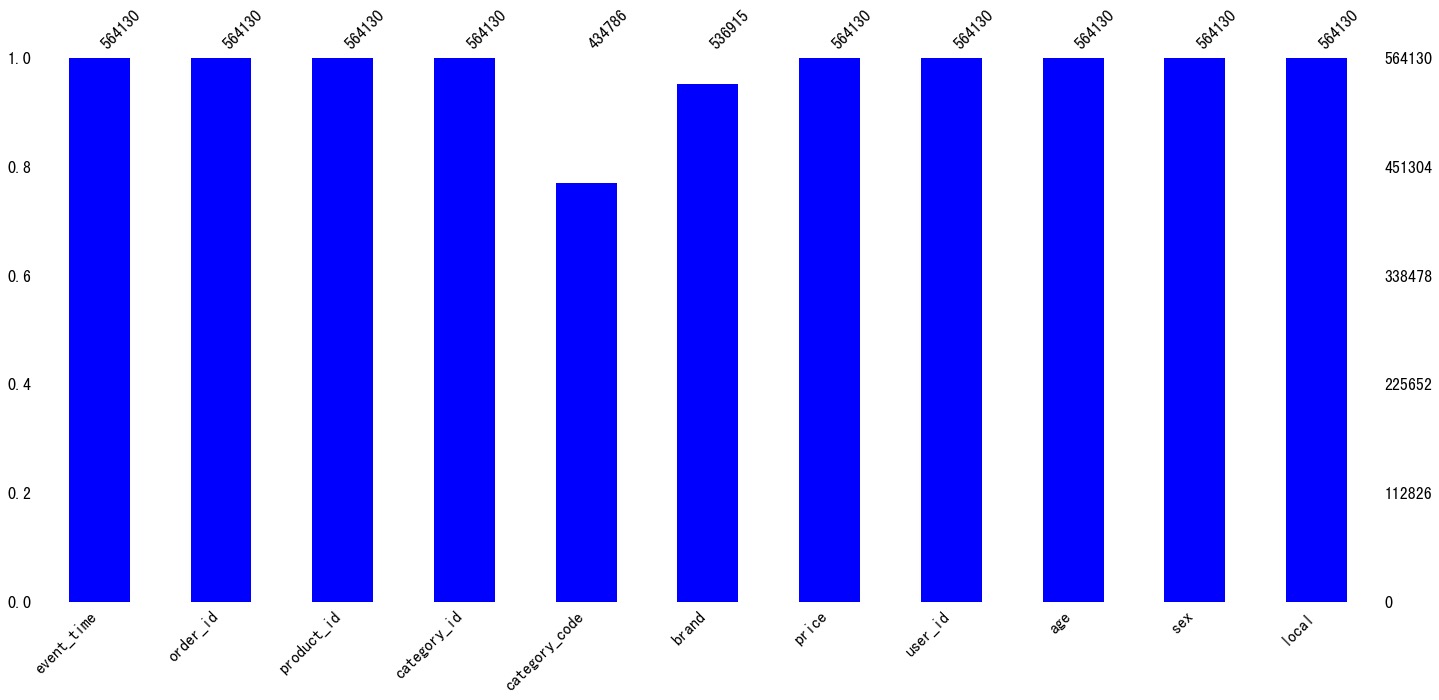
缺失值处理
缺失值情况
In [11]:
1 | df.isnull().sum() |
Out[11]:
1 | event_time 0 |
可以看到缺失值体现在字段:
- category_code:类别
- brand:品牌
In [12]:
1 | ms.bar(df,color="blue") |
缺失值填充
In [13]:
1 | df.fillna("missing",inplace=True) |
In [14]:
1 | df.isnull().sum() |
Out[14]:
1 | event_time 0 |
时间字段处理
字段类型转化
读进来的数据中时间字段是object类型,需要将其转成时间格式的类型
In [15]:
1 | df["event_time"][:5] # 处理前 |
Out[15]:
1 | 0 2020-04-24 11:50:39 UTC |
In [16]:
1 | # 去掉最后的UTC |
In [17]:
1 | # 时间数据类型转化:字符类型---->指定时间格式 |
字段衍生
In [18]:
1 | # 提取多个时间相关字段 |
In [19]:
1 | df["event_time"][:5] # 处理后 |
Out[19]:
1 | 0 2020-04-24 11:50:39 |
可以看到字段类型已经发生了变化
整体趋势分析
分析1:每月成交金额多少?
In [20]:
1 | amount_by_month = df.groupby("month")["price"]).) |
Out[20]:
| month | price | |
|---|---|---|
| 0 | 1 | 1953358.17 |
| 1 | 2 | 2267809.88 |
| 2 | 3 | 2897486.26 |
| 3 | 4 | 1704422.41 |
| 4 | 5 | 7768637.79 |
| 5 | 6 | 7691244.33 |
| 6 | 7 | 16354029.27 |
| 7 | 8 | 27982605.44 |
| 8 | 9 | 17152310.57 |
| 9 | 10 | 19765680.76 |
| 10 | 11 | 11961511.52 |
In [21]:
1 | fig = px.scatter(amount_by_month,x="month",y="price",size="price",color="price") |
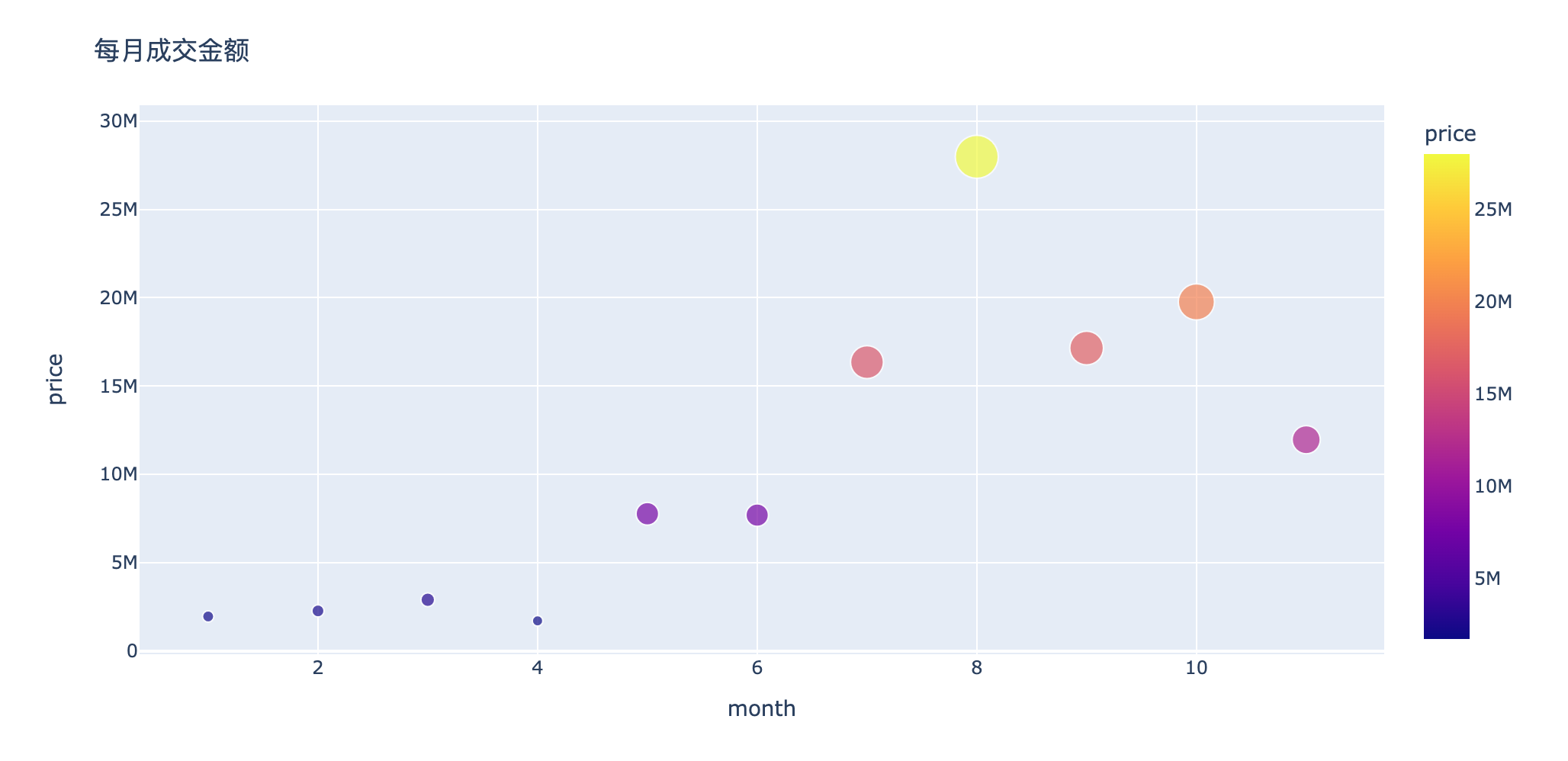
分析2:月订单量如何变化?
In [22]:
1 | order__month = df.groupby("month")["order_id"].nunique().reset_index() |
Out[22]:
| month | order_id | |
|---|---|---|
| 0 | 1 | 10353 |
| 1 | 2 | 11461 |
| 2 | 3 | 12080 |
| 3 | 4 | 9001 |
| 4 | 5 | 30460 |
| 5 | 6 | 28978 |
| 6 | 7 | 57659 |
| 7 | 8 | 73897 |
| 8 | 9 | 345 |
| 9 | 10 | 14 |
| 10 | 11 | 6 |
In [23]:
1 | fig = px.line(order_by_month,x="month",y="order_id") |
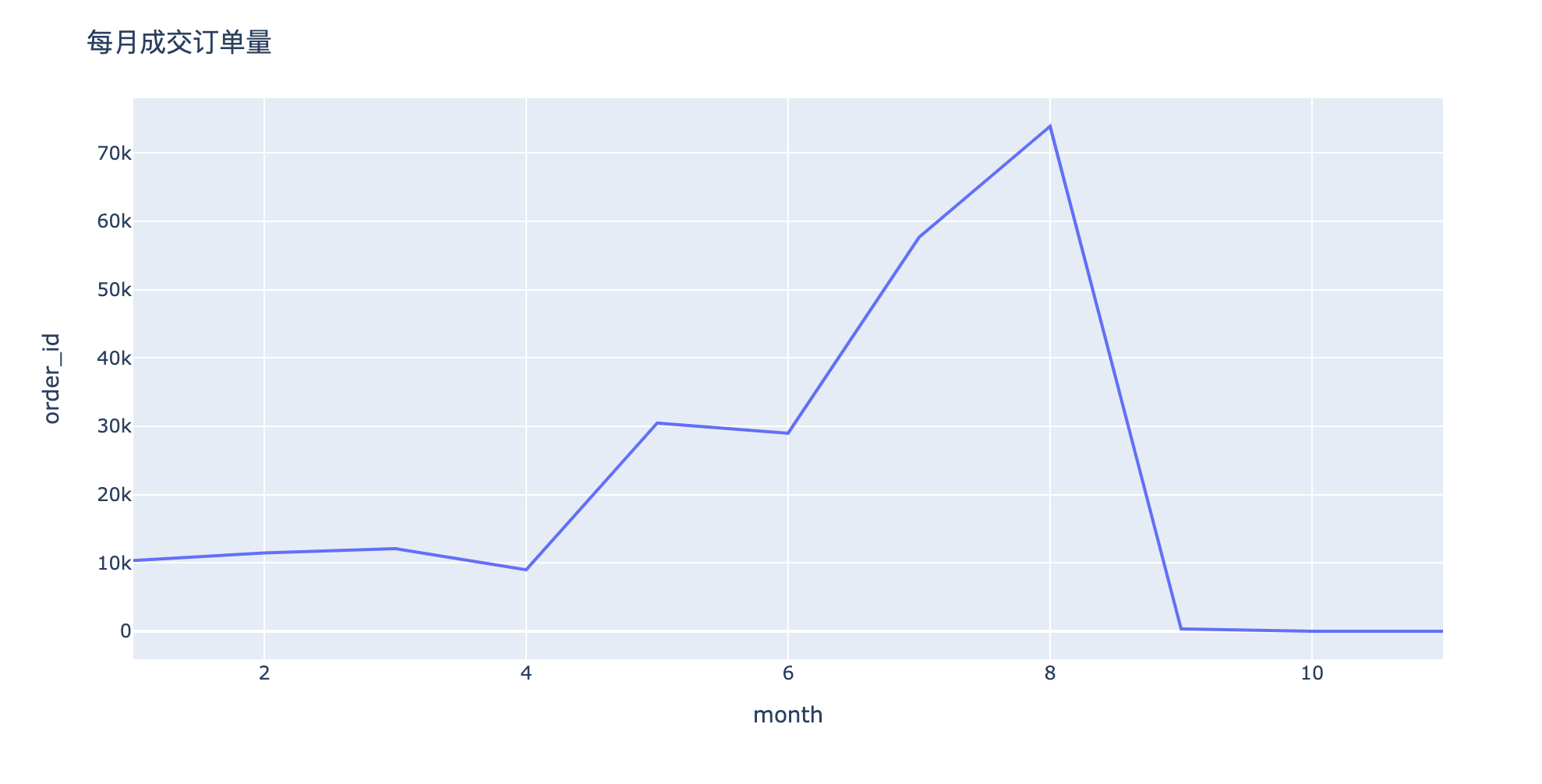
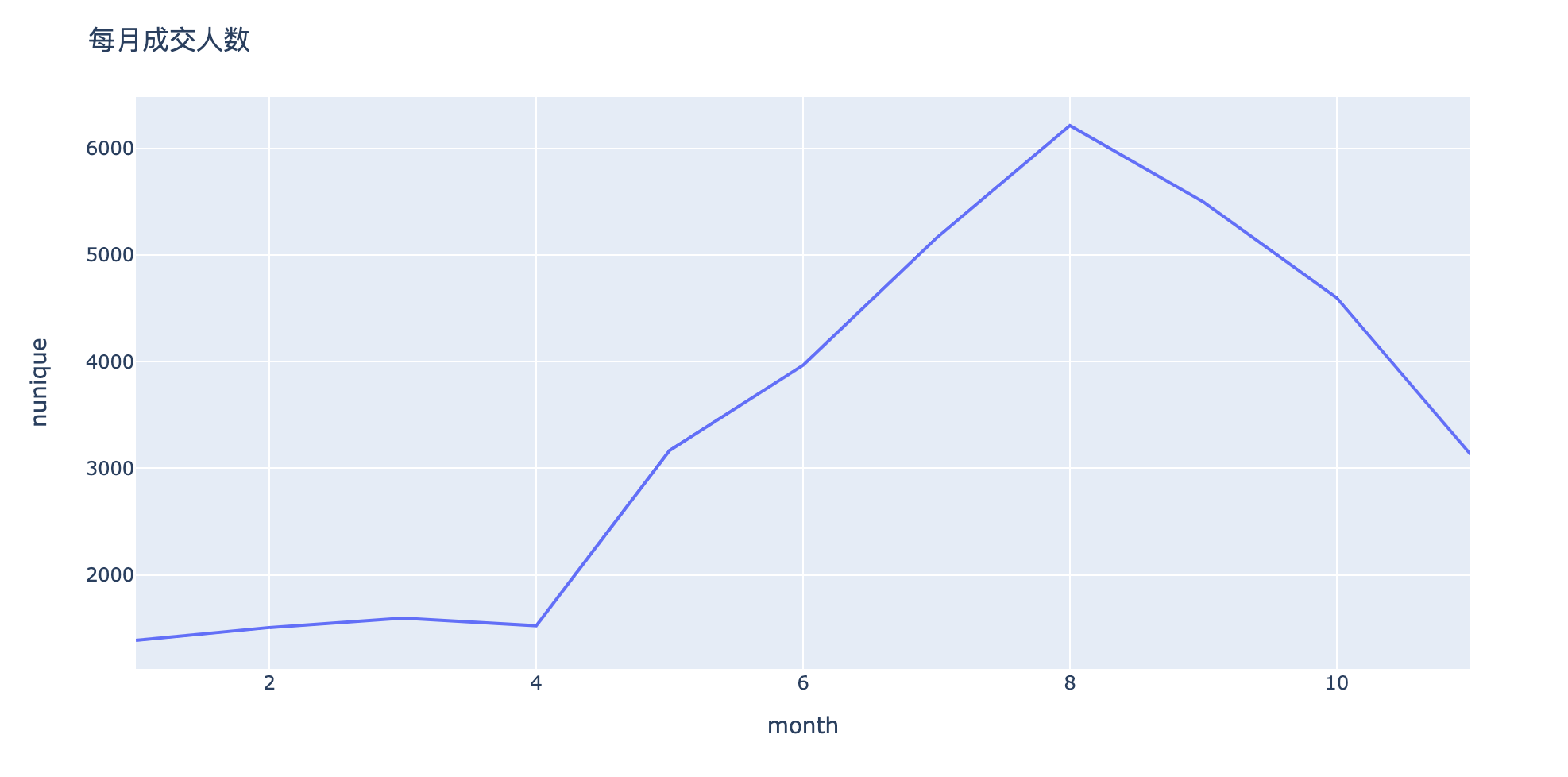
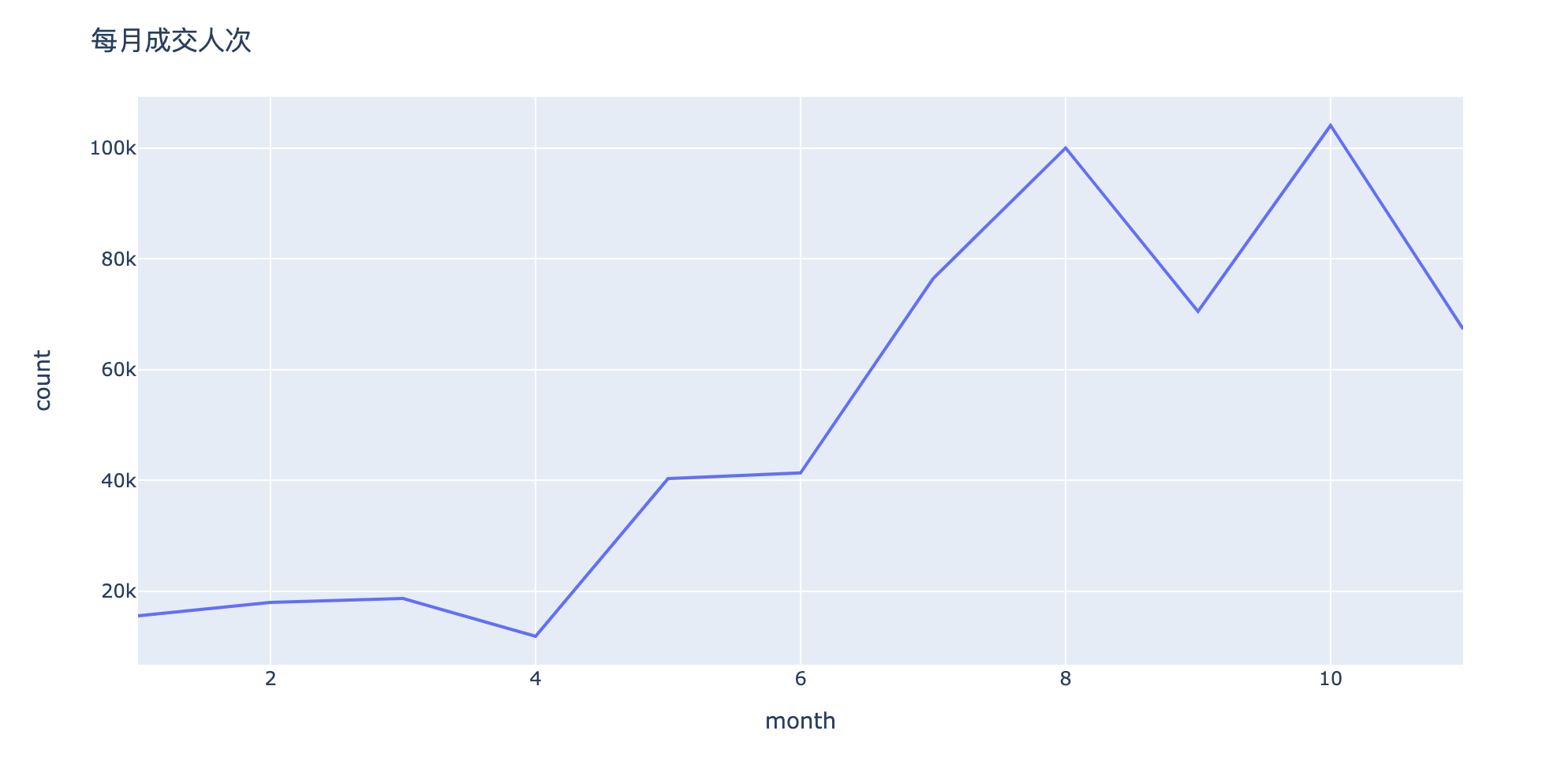
分析3:月消费人数/人次如何变化?
In [24]:
1 | # nunique:对每个user_id进行去重:消费人数 |
Out[24]:
| month | nunique | count | |
|---|---|---|---|
| 0 | 1 | 1388 | 15575 |
| 1 | 2 | 1508 | 17990 |
| 2 | 3 | 1597 | 18687 |
| 3 | 4 | 1525 | 11867 |
| 4 | 5 | 3168 | 40332 |
| 5 | 6 | 3966 | 41355 |
| 6 | 7 | 5159 | 76415 |
| 7 | 8 | 6213 | 100006 |
| 8 | 9 | 5497 | 70496 |
| 9 | 10 | 4597 | 104075 |
| 10 | 11 | 3134 | 67332 |
In [25]:
1 | fig = px.line(people_by_month,x="month",y="nunique") |
1 | fig = px.line(people_by_month,x="month",y="count") |
分析4:每月客单价多少?
In [27]:
1 | amount_by_month # 每月成交金额 |
Out[27]:
| month | price | |
|---|---|---|
| 0 | 1 | 1953358.17 |
| 1 | 2 | 2267809.88 |
| 2 | 3 | 2897486.26 |
| 3 | 4 | 1704422.41 |
| 4 | 5 | 7768637.79 |
| 5 | 6 | 7691244.33 |
| 6 | 7 | 16354029.27 |
| 7 | 8 | 27982605.44 |
| 8 | 9 | 17152310.57 |
| 9 | 10 | 19765680.76 |
| 10 | 11 | 11961511.52 |
In [28]:
1 | order_by_month # 每月订单数 |
Out[28]:
| month | order_id | |
|---|---|---|
| 0 | 1 | 10353 |
| 1 | 2 | 11461 |
| 2 | 3 | 12080 |
| 3 | 4 | 9001 |
| 4 | 5 | 30460 |
| 5 | 6 | 28978 |
| 6 | 7 | 57659 |
| 7 | 8 | 73897 |
| 8 | 9 | 345 |
| 9 | 10 | 14 |
| 10 | 11 | 6 |
In [29]:
1 | amount__userid = pd.merge(amount__month,order__month) |
Out[29]:
| month | price | order_id | |
|---|---|---|---|
| 0 | 1 | 1953358.17 | 10353 |
| 1 | 2 | 2267809.88 | 11461 |
| 2 | 3 | 2897486.26 | 12080 |
| 3 | 4 | 1704422.41 | 9001 |
| 4 | 5 | 7768637.79 | 30460 |
| 5 | 6 | 7691244.33 | 28978 |
| 6 | 7 | 16354029.27 | 57659 |
| 7 | 8 | 27982605.44 | 73897 |
| 8 | 9 | 17152310.57 | 345 |
| 9 | 10 | 19765680.76 | 14 |
| 10 | 11 | 11961511.52 | 6 |
In [30]:
1 | amount__userid["average"] = amount__userid["price"] / amount__userid["order_id"] |
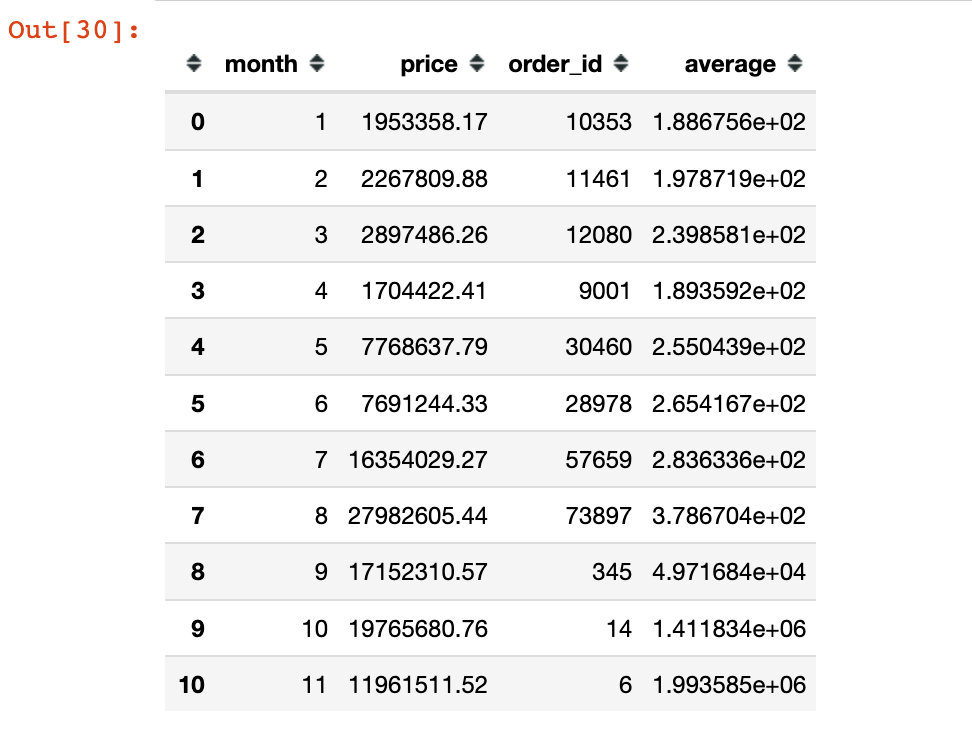
1 | fig = px.line(amount_by_userid,x="month",y="average") |
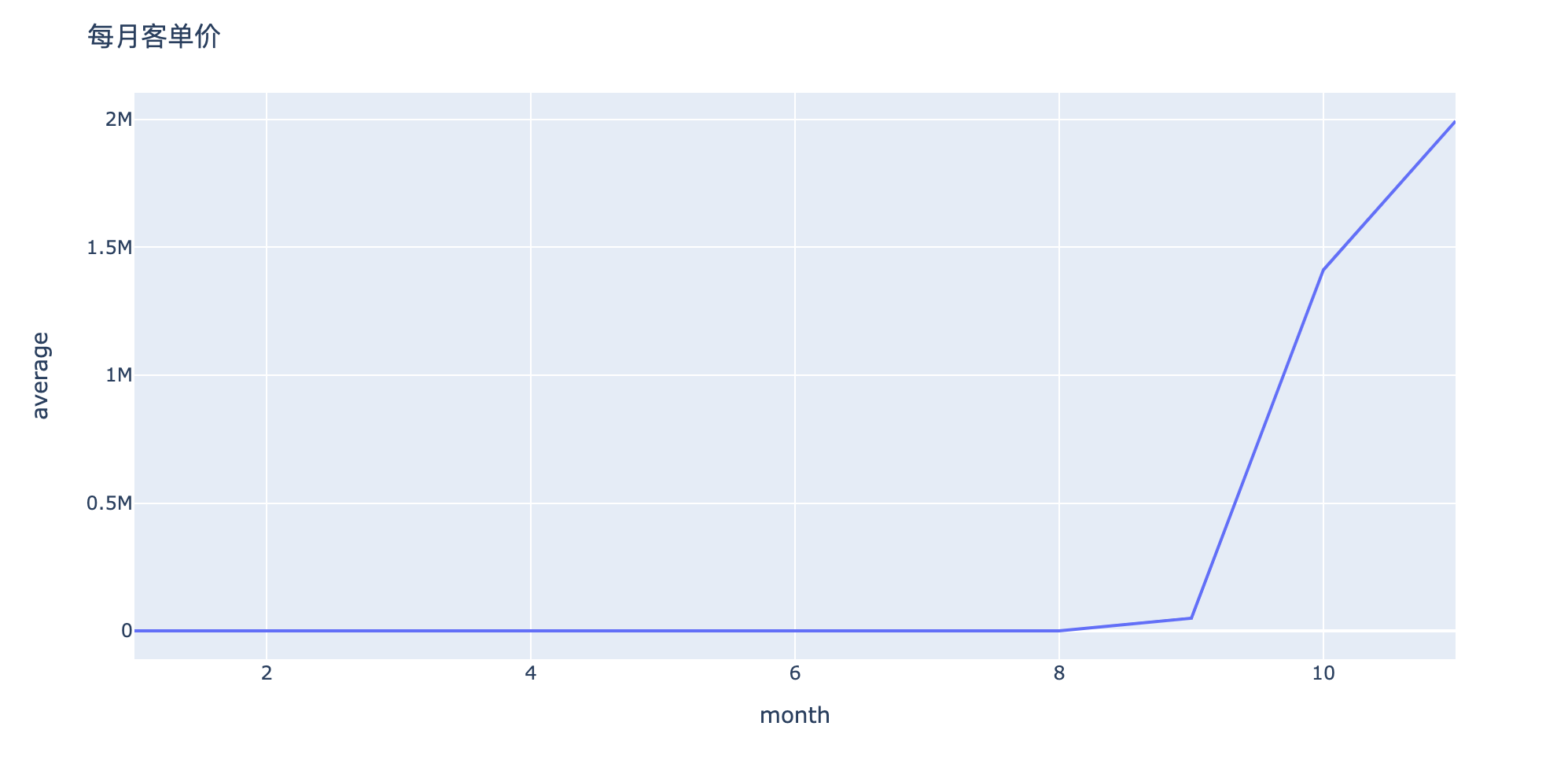
分析5:每个订单包含多少产品
In [32]:
1 | product_by_order = df.groupby("order_id")["product_id"].count().reset_index().sort_values("product_id",ascending=False) |
Out[32]:
| order_id | product_id | |
|---|---|---|
| 234208 | 2388440981134640000 | 15021 |
| 234210 | 2388440981134660000 | 14891 |
| 234211 | 2388440981134670000 | 14845 |
| 234212 | 2388440981134680000 | 14765 |
| 234202 | 2388440981134580000 | 14587 |
| 234205 | 2388440981134610000 | 14571 |
| 234207 | 2388440981134630000 | 14443 |
| 234204 | 2388440981134600000 | 14416 |
| 234206 | 2388440981134620000 | 14414 |
| 234203 | 2388440981134590000 | 14194 |
In [33]:
1 | fig = px.bar(product_by_order[:20], |
不同省份对比
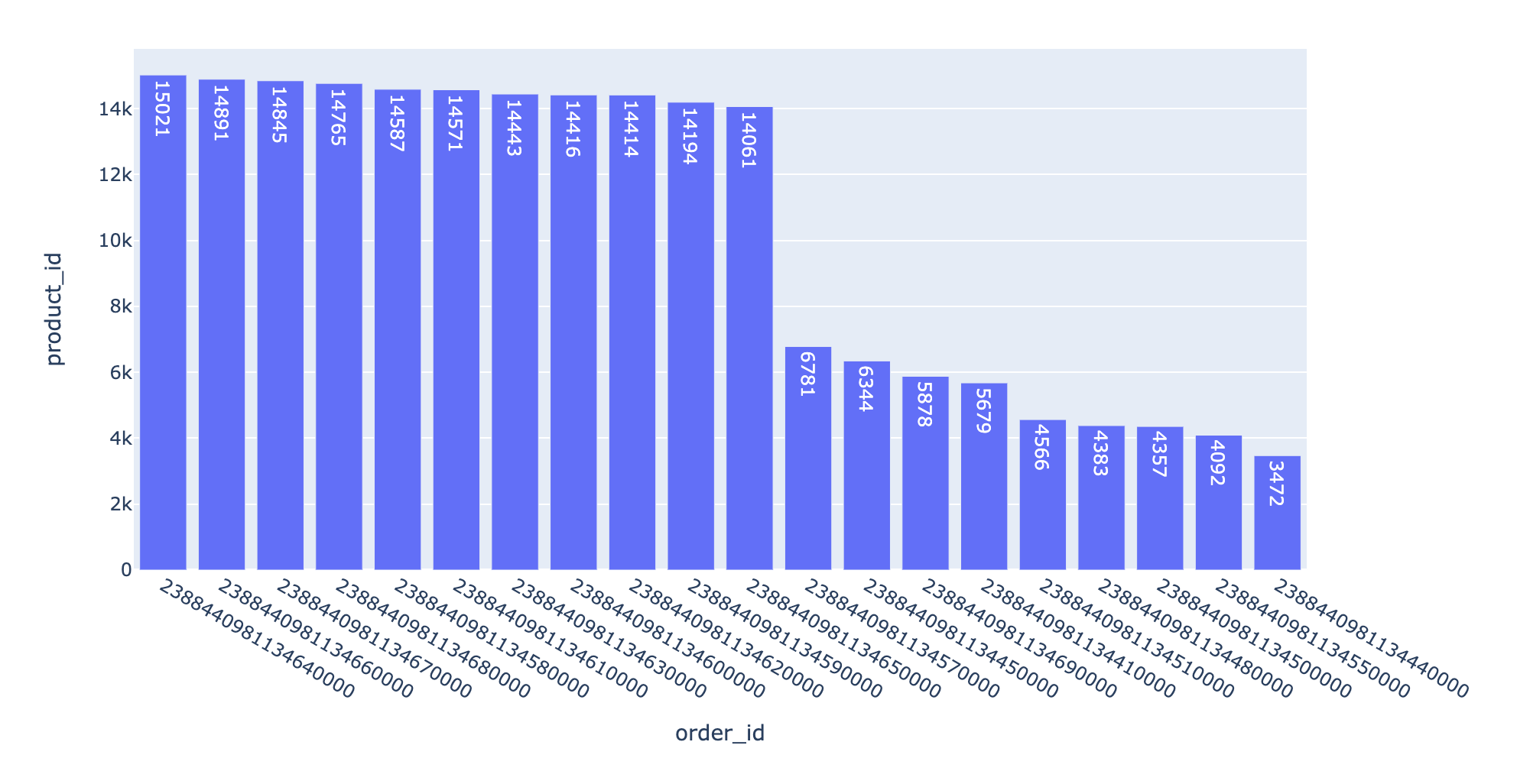
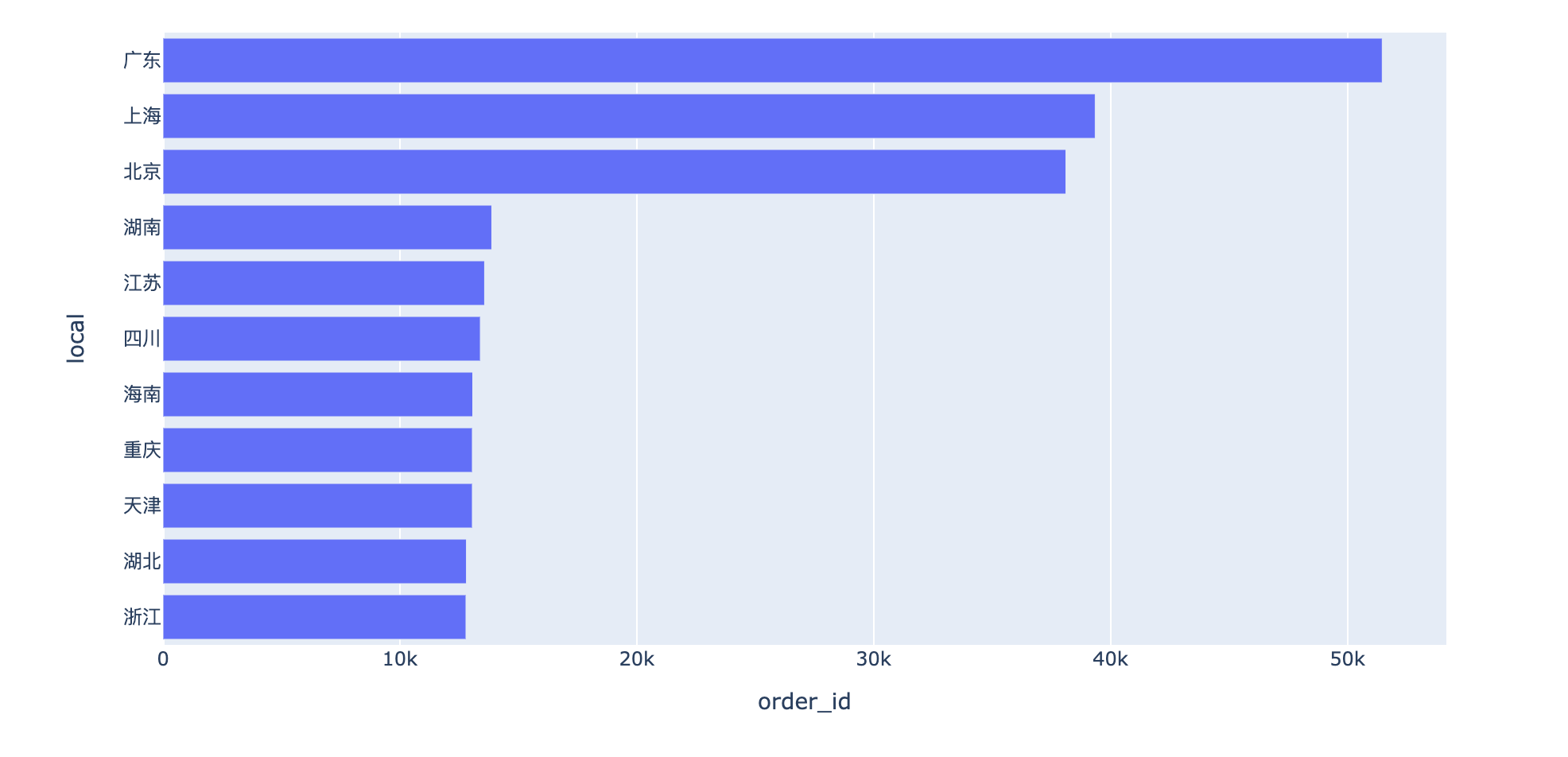
分析6:订单量、用户量和成交金额对比
不同省份下的订单量、用户量和成交金额对比
In [34]:
1 | local = df.groupby("local").agg({"order_id":"nunique","user_id":"nunique","price":sum}).reset_index() |
Out[34]:
| local | order_id | user_id | price | |
|---|---|---|---|---|
| 0 | 上海 | 39354 | 5680 | 19837942.20 |
| 1 | 北京 | 38118 | 5702 | 19137748.75 |
| 2 | 四川 | 13396 | 3589 | 6770891.28 |
| 3 | 天津 | 13058 | 3497 | 6433736.85 |
| 4 | 广东 | 51471 | 6085 | 26013770.86 |
In [35]:
1 | df1 = local.sort_values("order_id",ascending=True) |
Out[35]:
| local | order_id | user_id | price | |
|---|---|---|---|---|
| 6 | 浙江 | 12790 | 3485 | 6522657.59 |
| 8 | 湖北 | 12810 | 3488 | 5993820.57 |
| 3 | 天津 | 13058 | 3497 | 6433736.85 |
| 10 | 重庆 | 13058 | 3496 | 6479488.14 |
| 7 | 海南 | 13076 | 3587 | 6968674.41 |
| 2 | 四川 | 13396 | 3589 | 6770891.28 |
| 5 | 江苏 | 13575 | 3598 | 6357286.87 |
| 9 | 湖南 | 13879 | 3481 | 6983078.88 |
| 1 | 北京 | 38118 | 5702 | 19137748.75 |
| 0 | 上海 | 39354 | 5680 | 19837942.20 |
| 4 | 广东 | 51471 | 6085 | 26013770.86 |
In [36]:
1 | fig = px.pie(df1, names="local",labels="local",values="price") |
每个省份的订单量对比:
1 | fig = px.bar(df1,x="order_id",y="local",orientation="h") |
1 | # 整体的可视化效果 |
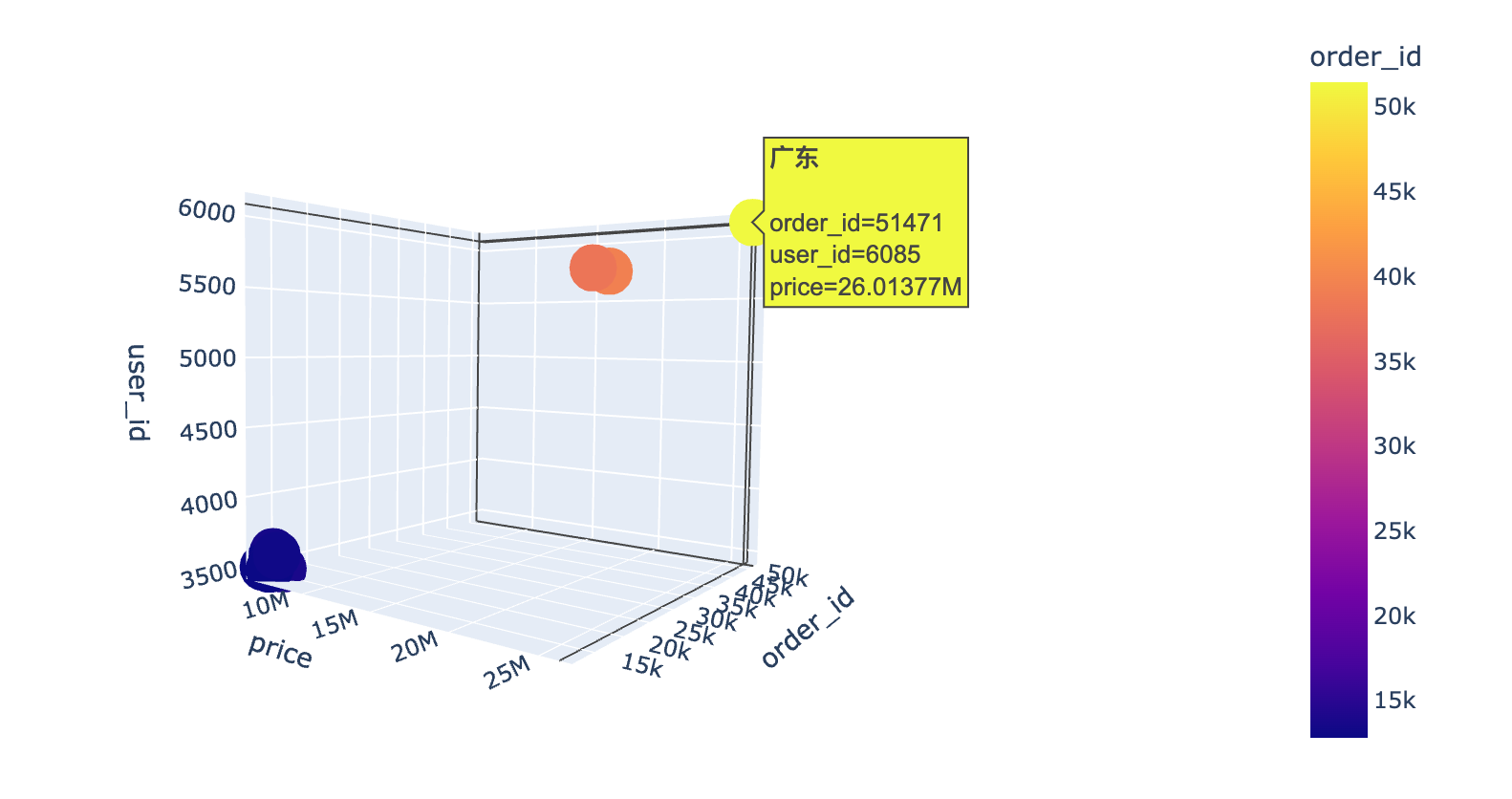
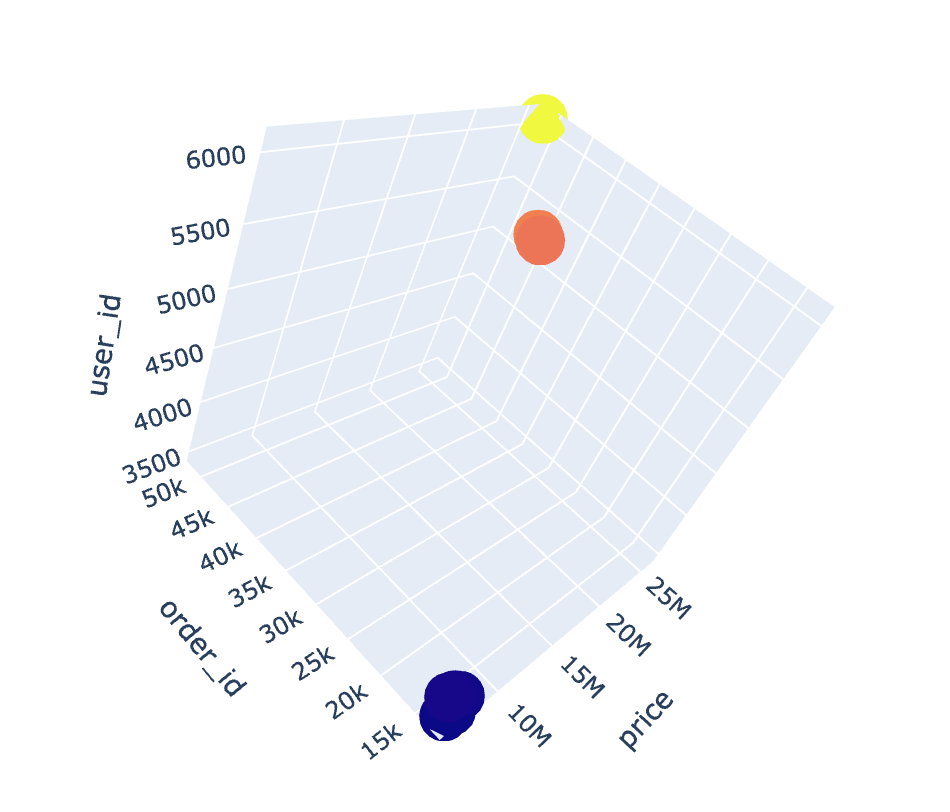
通过3D散点图我们发现:广东省真的是一骑绝尘!
分析7:不同省份的客户钟爱哪些品牌?
In [39]:
1 | local_brand = df.groupby(["local","brand"]).size().to_frame().reset_index() |

1 | # 根据local和number进行排序 |
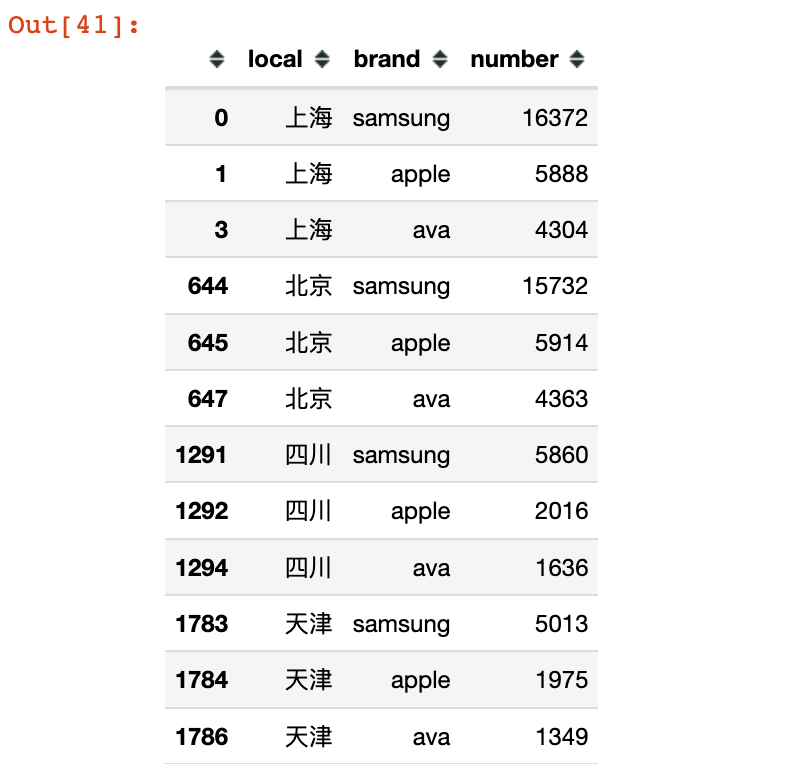
1 | fig = px.bar(local_brand, |
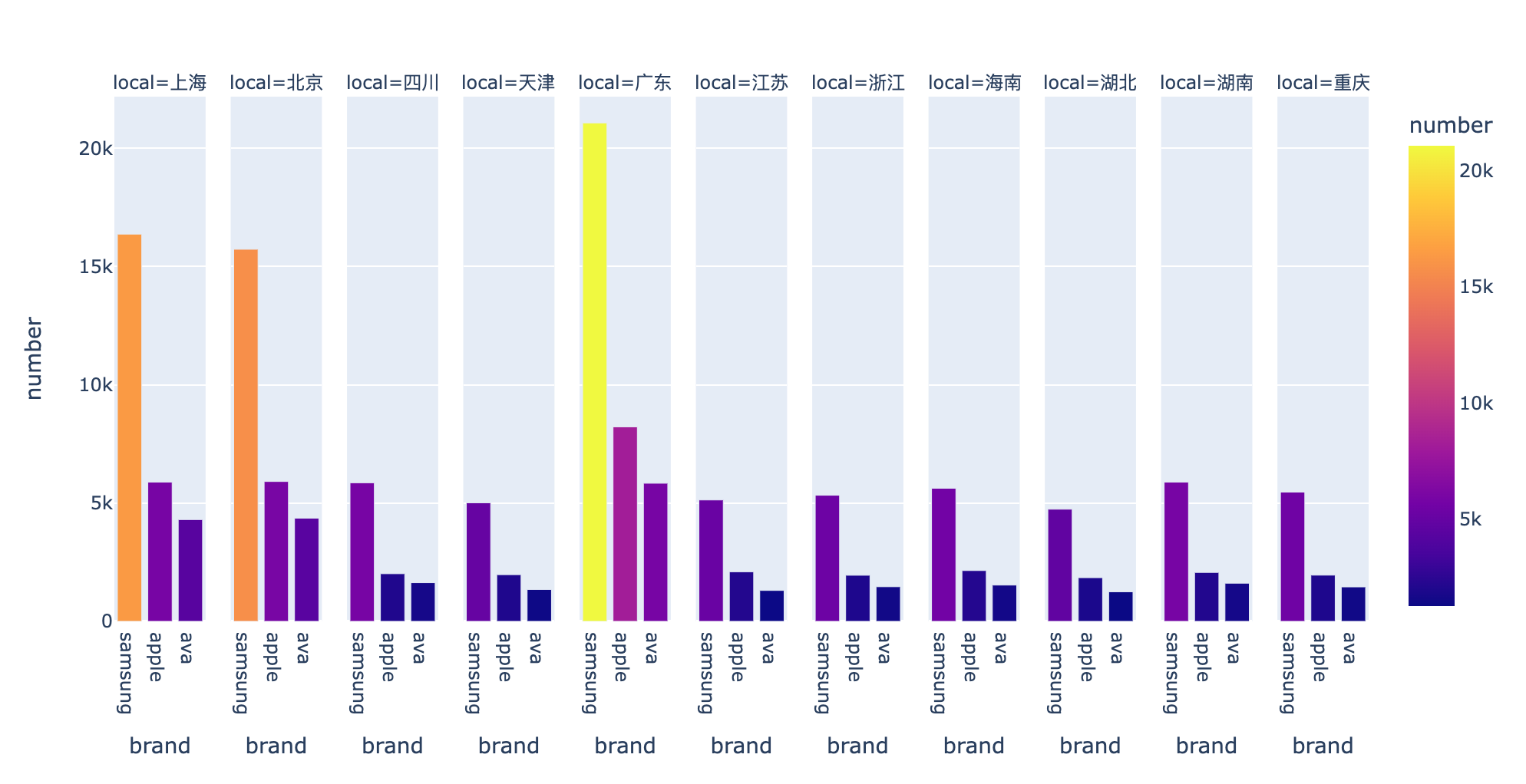
不同时间对比
分析8:下单时间对比
In [43]:
1 | df.columns |
Out[43]:
1 | Index(['event_time', 'order_id', 'product_id', 'category_id', 'category_code', |
In [44]:
1 | df2 = df.groupby("dayofweek")["order_id"].nunique().reset_index() |
Out[44]:
| dayofweek | order_id | |
|---|---|---|
| 0 | 0 | 35690 |
| 1 | 1 | 34256 |
| 2 | 2 | 31249 |
| 3 | 3 | 31555 |
| 4 | 4 | 33010 |
| 5 | 5 | 34772 |
| 6 | 6 | 33922 |
In [45]:
1 | plt.figure(figsize=(12,7)) |
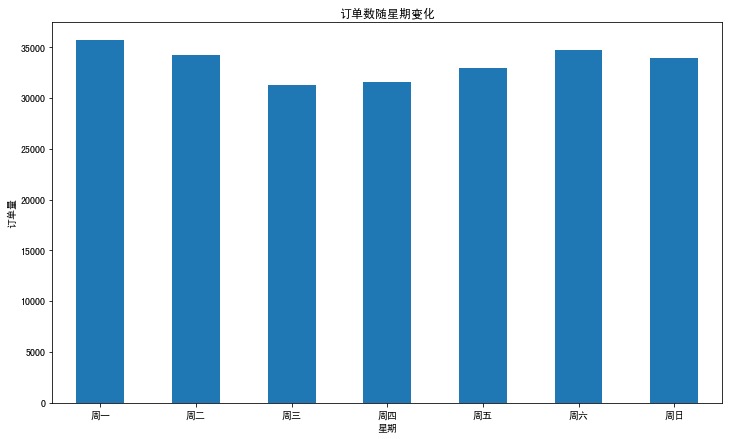
分析9:每小时订单量
In [46]:
1 | df3 = df.groupby("hour")["order_id"].nunique().reset_index() |
Out[46]:
| hour | order_id | |
|---|---|---|
| 0 | 0 | 2865 |
| 1 | 1 | 2711 |
| 2 | 2 | 3981 |
| 3 | 3 | 6968 |
| 4 | 4 | 12176 |
| 5 | 5 | 16411 |
| 6 | 6 | 18667 |
| 7 | 7 | 20034 |
| 8 | 8 | 20261 |
| 9 | 9 | 20507 |
In [47]:
1 | plt.figure(figsize=(14,8)) |
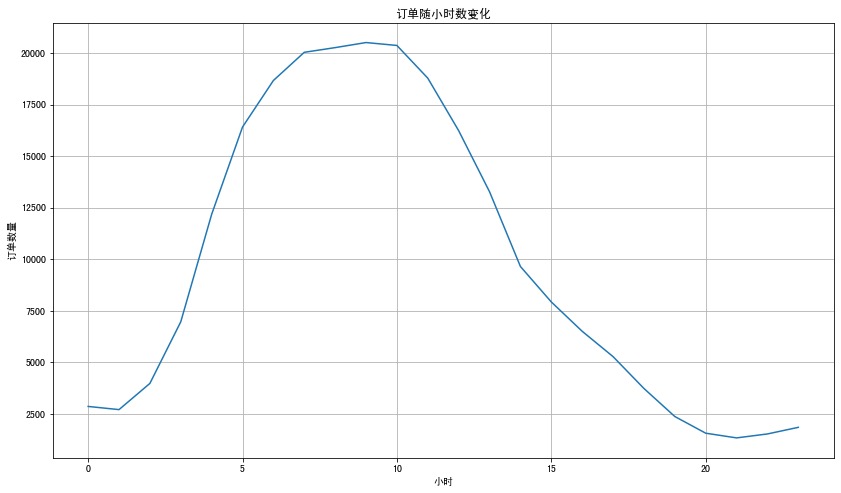
不同用户消费行为分析
分析10:消费次数和消费金额
In [48]:
1 | df4 = df.groupby("user_id").agg({"order_id":"nunique", "price":sum}) |
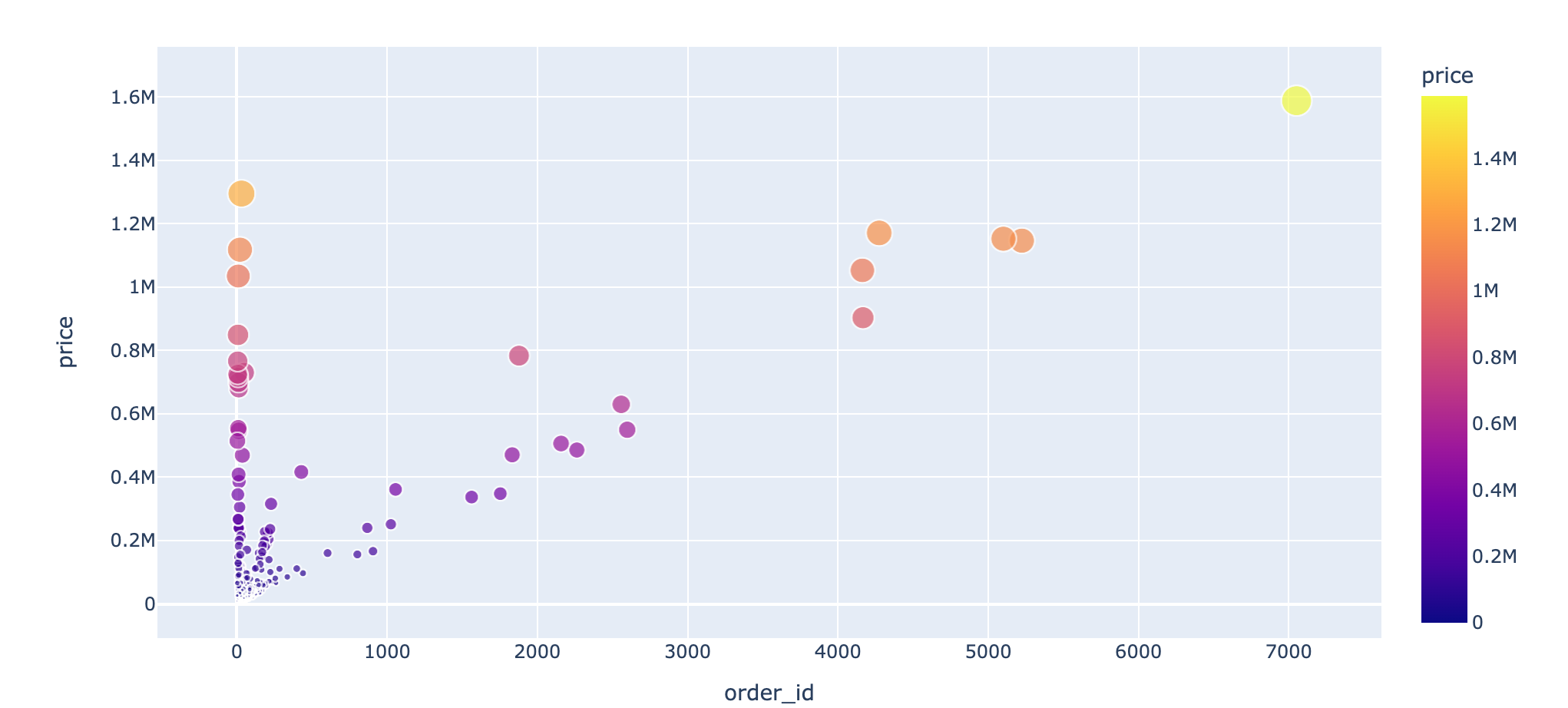
分析11:用户消费周期
In [50]:
1 |
|
Out[50]:
1 | user_id |
In [51]:
1 | purchase_time[purchase_time>0].describe() |
Out[51]:
1 | count 120629.000000 |
说明:
- 至少消费两次的用户的消费周期是4天
- 有75%的客户消费周期在12天
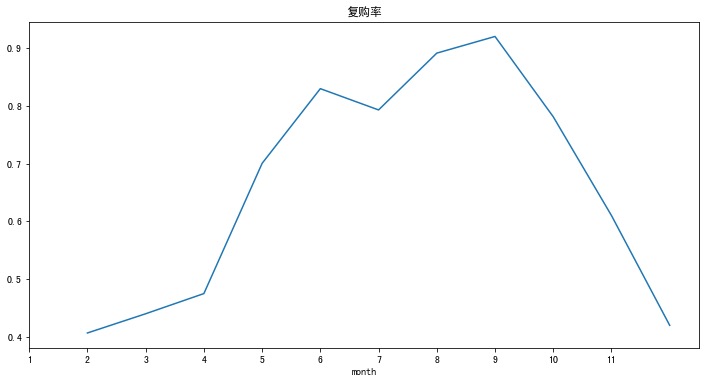
分析12:用户复购行为
In [52]:
1 | pivoted_counts = df.pivot_table(index='user_id', |
Out[52]:
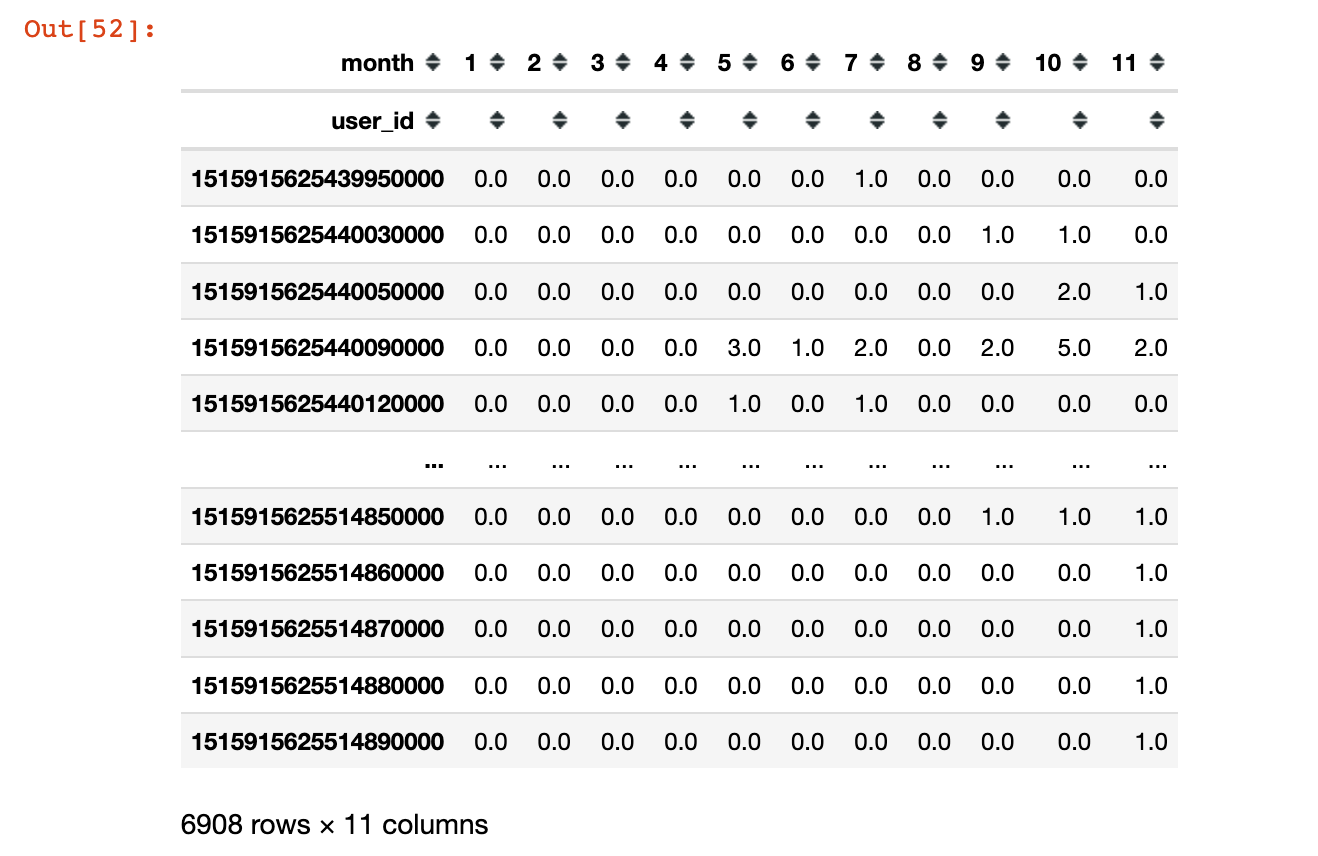
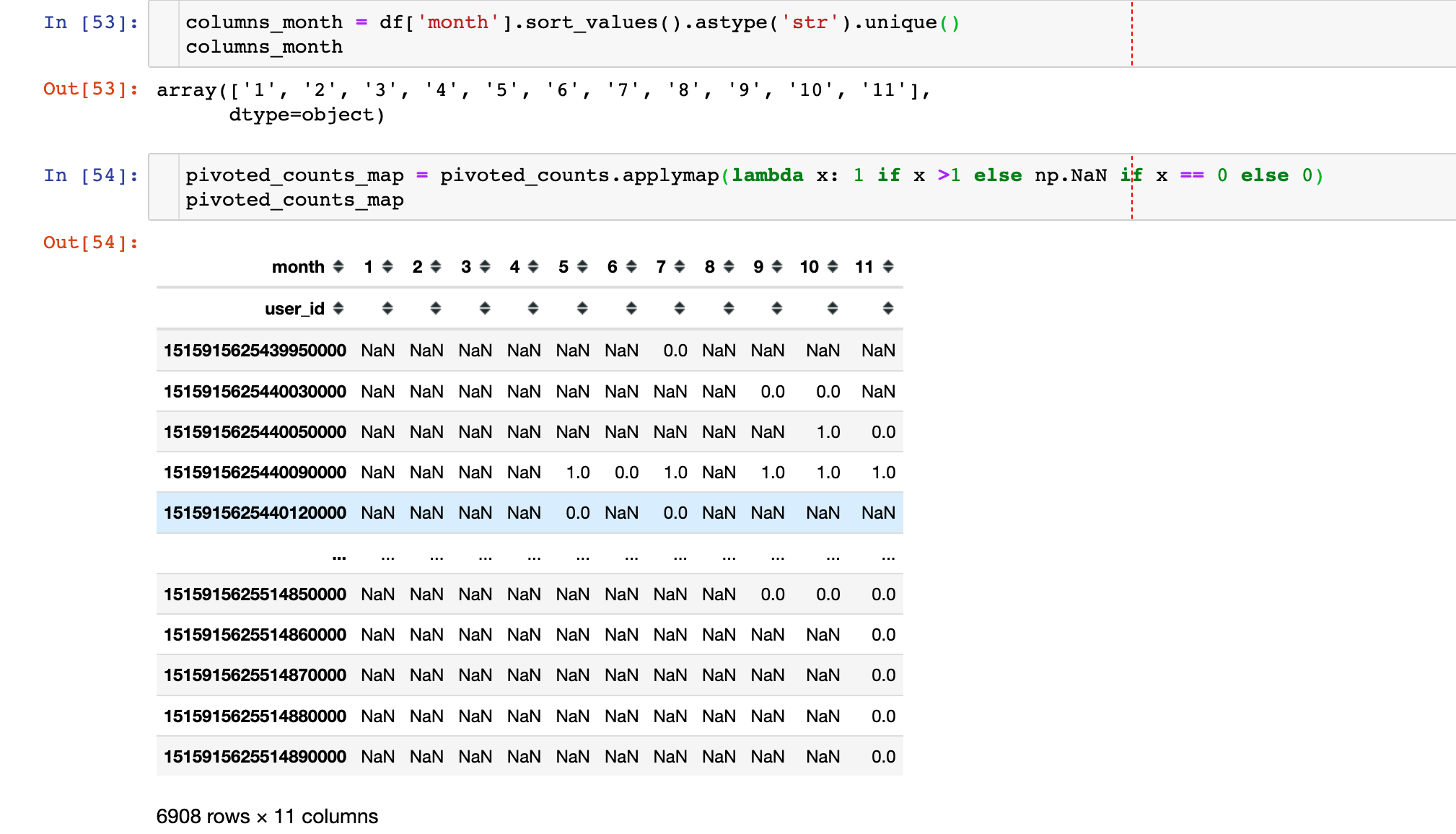
1 | pivoted_counts_map.sum() / pivoted_counts_map.count() |
1 | (pivoted_counts_map.sum()/pivoted_counts_map.count()).plot(figsize=(12,6)) |