
机器学习算法竞赛实战-数据探索
本文是《机器学习算法竞赛实战》的读书笔记2:在进行建模之前如何进行数据探索,了解数据的基本情况。通过系统的探索加深对数据的理解。

数据探索
分析思路是什么
最好使用多种思路和方法来探索每个变量并比较结果。
分析方法有哪些
- 单变量可视化分析
- 多变量可视化分析
- 降维分析
明确分析目的
如果跳过数据探索阶段或者只做肤浅的分析工作,可能导致数据倾斜,出现异常值或者缺失值。
数据探索的目的:
- 用于回答业务问题,测试业务假设,生成进一步分析的假设
- 为后面的建模准备数据
7大必做事
数据探索阶段必须做的7件事:
- 数据集基本情况
- 重复值、缺失值、异常值处理
- 特征冗余:比如单位cm和m
- 是否存在时间信息:时间的相关性、趋势性、周期性等分析
- 标签分布:对于分类问题,是否存在类别分布不均衡;对于回归问题,是否存在异常值,整体分布如何,是否需要进行目标转换
- 训练集和测试集的分布:是否有测试集中存在的特征字段,但是训练集中没有
- 单变量/多变量分布:熟悉特征的分布情况,以及特征和标签的对应关系
数据描述信息
- df.describe:查看数据的分布,得到多个统计量信息
- df.head:查看前N条数据信息,默认前5条
- df.shape:数据集的形状,行列数
- df.info:快速获得对数据集的简单描述,比如每个变量的类型、数据集的大小和缺失值等情况
In [1]:
1 | import pandas as pd |
导入数据:
In [2]:
1 | train = pd.read_csv("train.csv") |
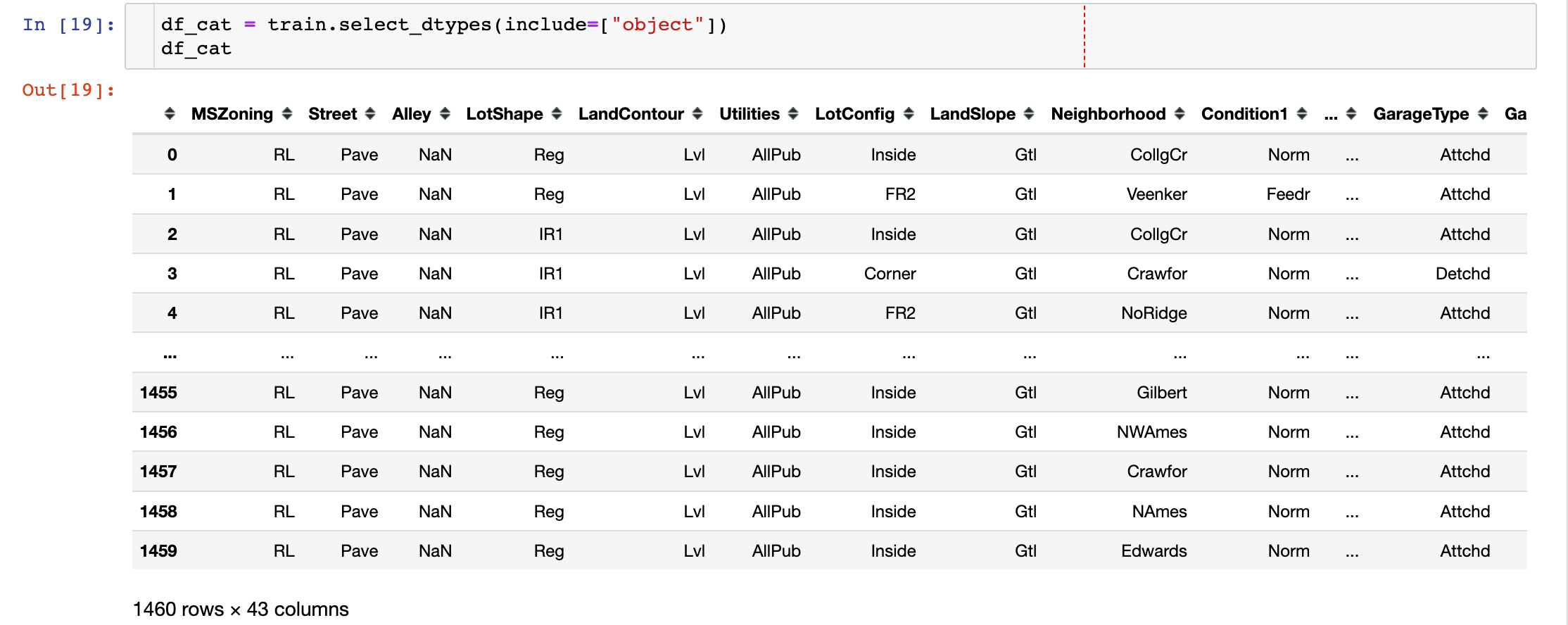
展示特征字段的nunique和缺失值情况:
In [3]:
1 | train.head() |
Out[3]:
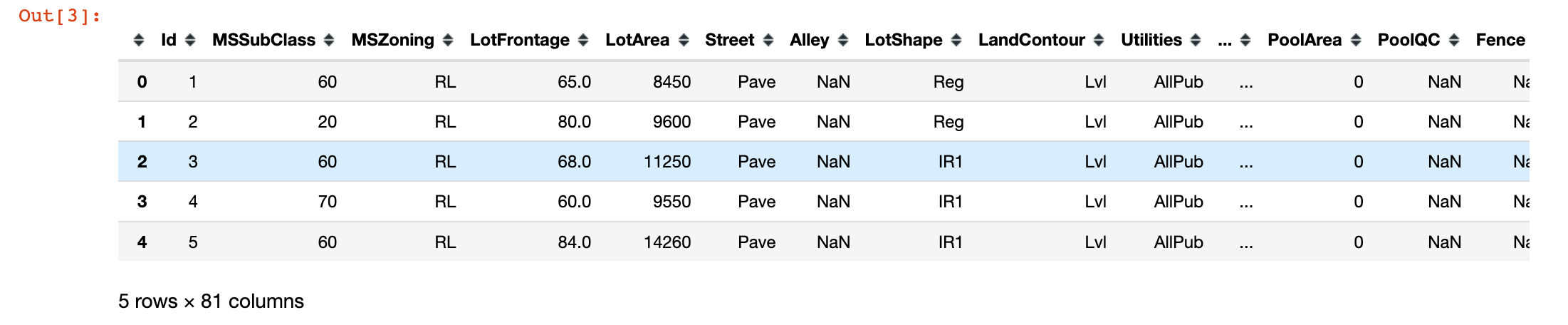
字段的缺失值情况:
In [4]:
1 | train.isnull().sum() |
Out[4]:
1 | Id 0 |
In [5]:
1 | train["LotFrontage"].value_counts(normalize=True,dropna=True) |
Out[5]:
1 | 60.0 0.119067 |
In [6]:
1 | train["LotFrontage"].value_counts(normalize=True) |
Out[6]:
1 | 60.0 0.119067 |
字段唯一值情况
In [7]:
1 | stats = [] |
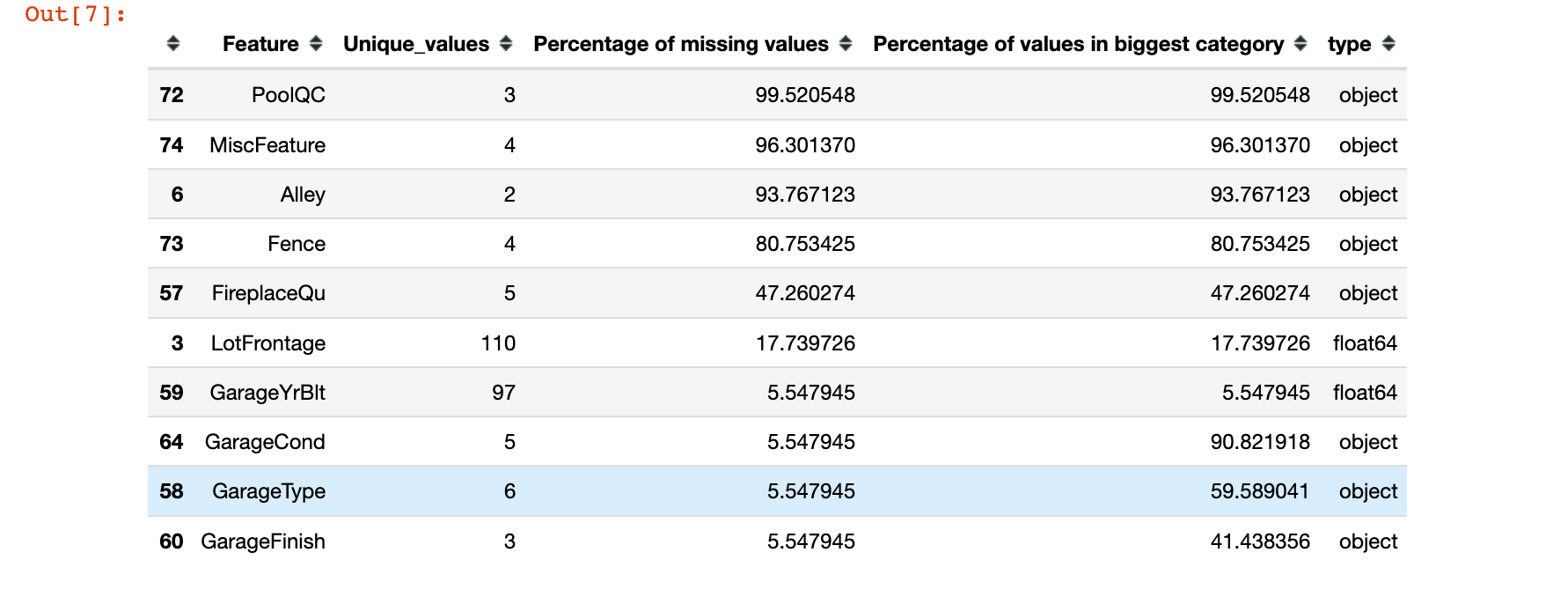
缺失值
使用柱状图直观显示缺失值分布情况:
In [8]:
1 | = train.isnull()) |
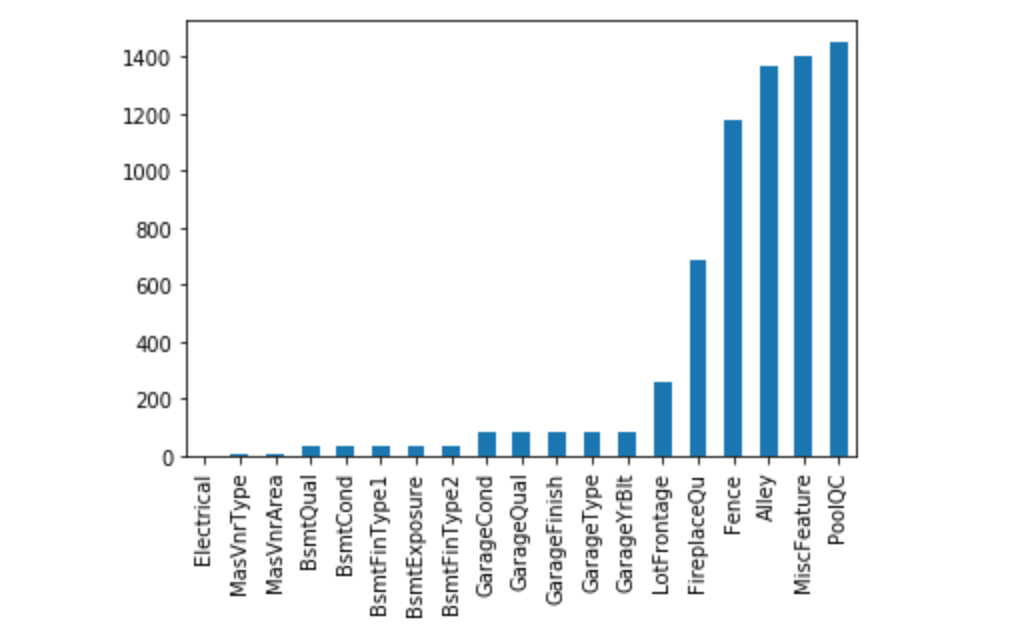
变量分析
- 单变量或者多变量分析
- 变量和标签间的相关性,并且进行假设检验
单变量分析
单变量分为:
- 标签
- 连续型
- 类别型
标签
In [9]:
1 | train["SalePrice"].describe() |
Out[9]:
1 | count 1460.000000 |
In [10]:
1 | # 可视化查看数据分布情况 |
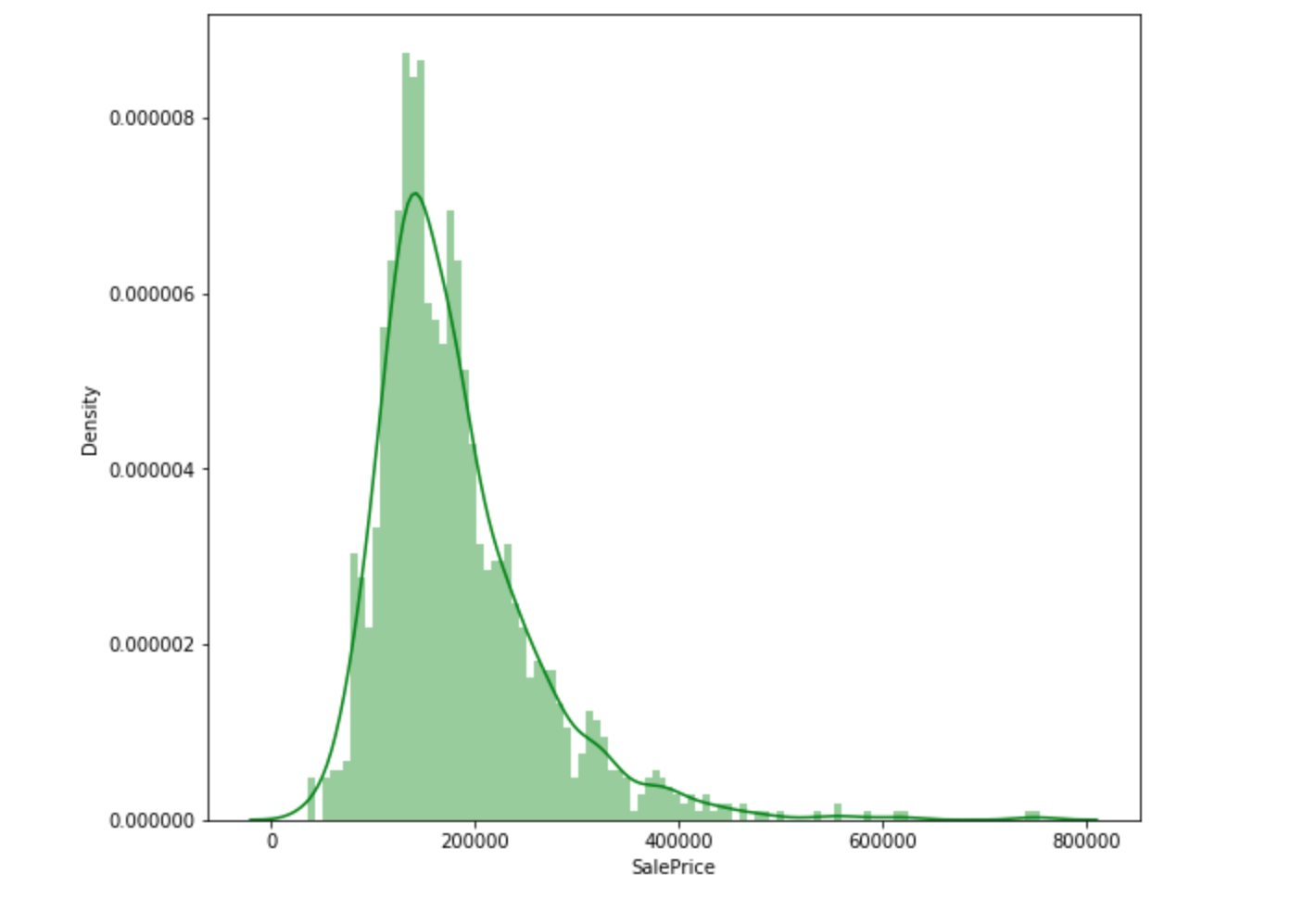
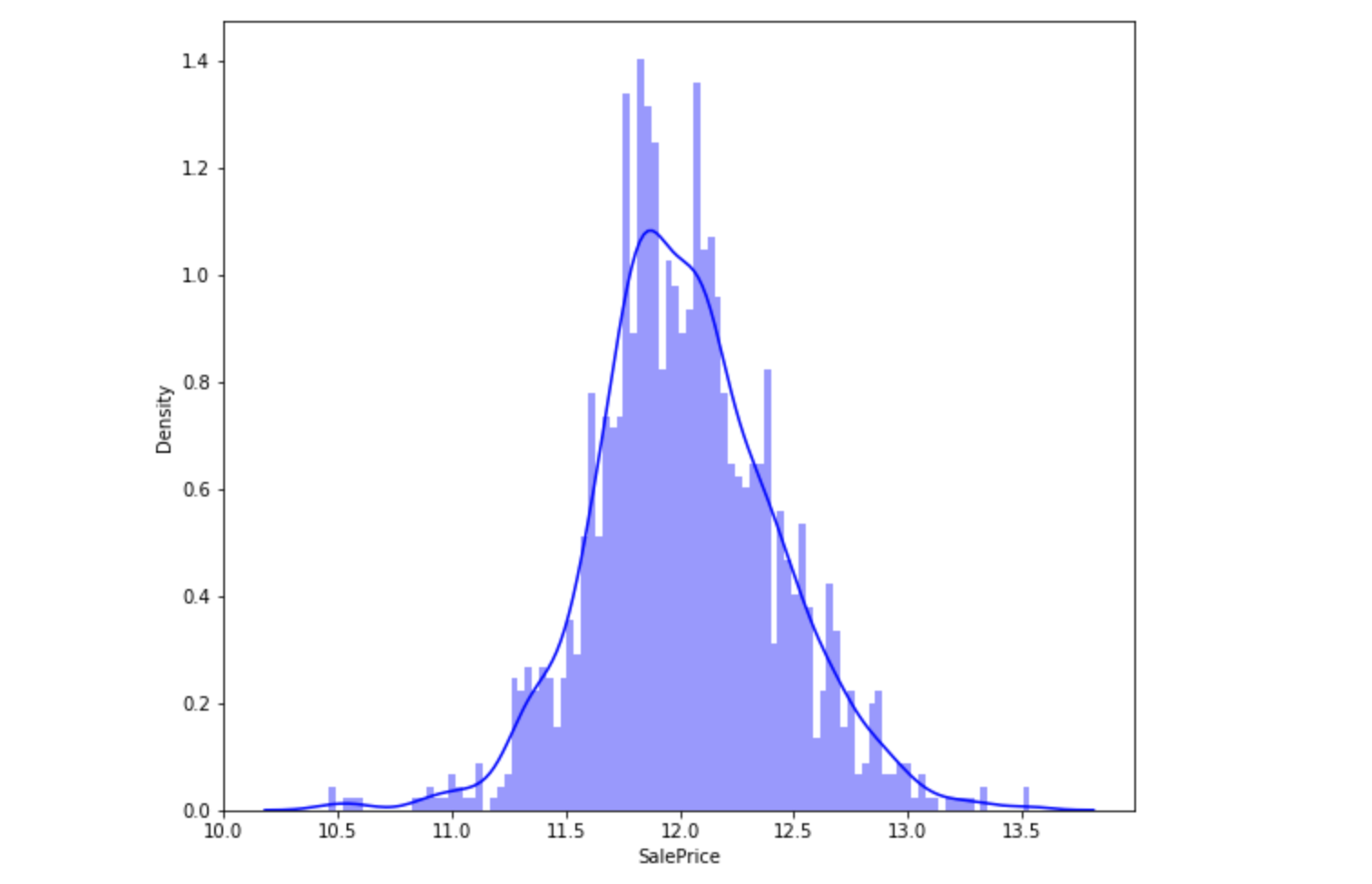
小结:数据呈现正态分布,向右倾斜,存在峰值。
对字段的取值进行取对数操作:
In [11]:
1 | # 取对数np.log |
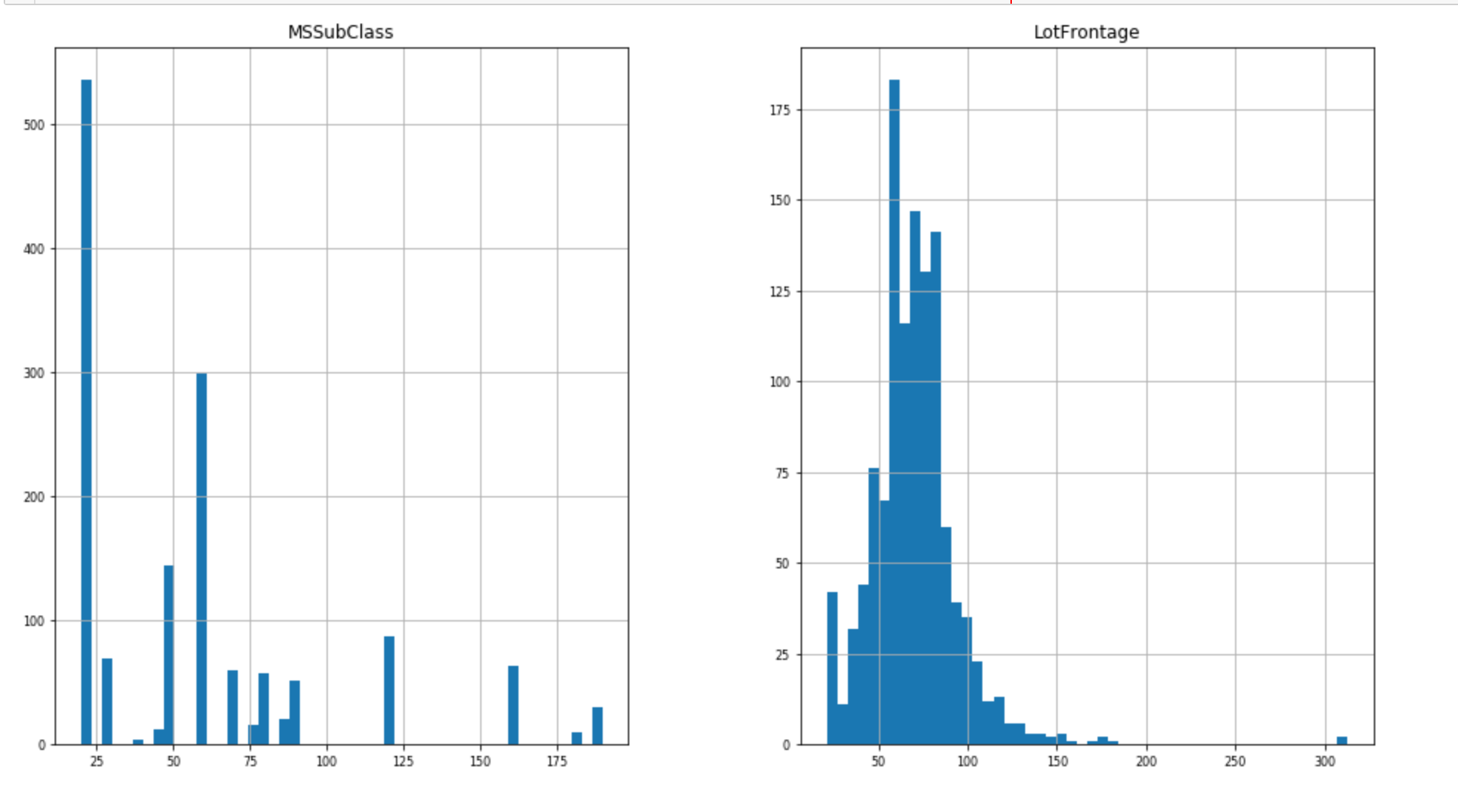
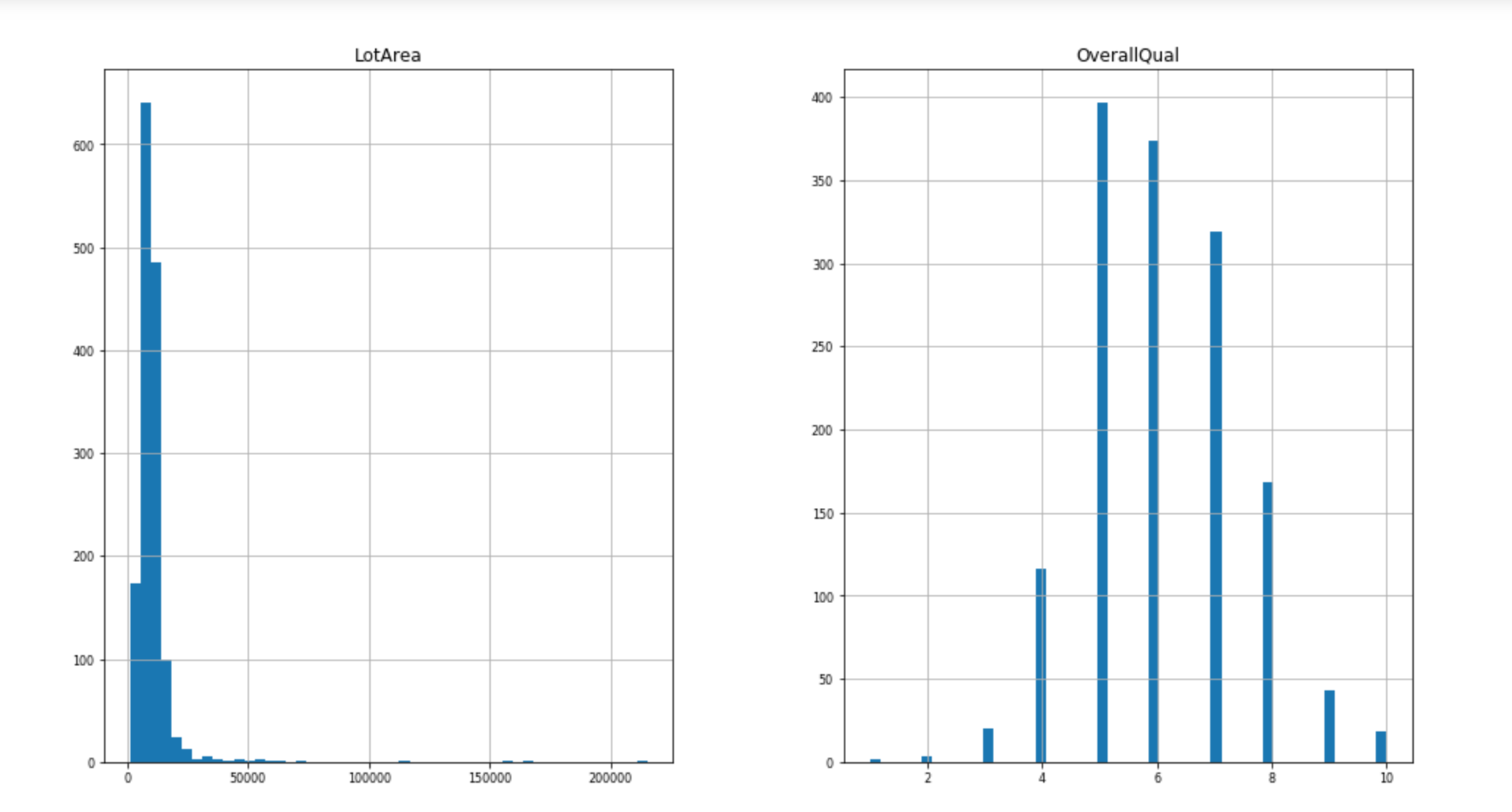
连续型
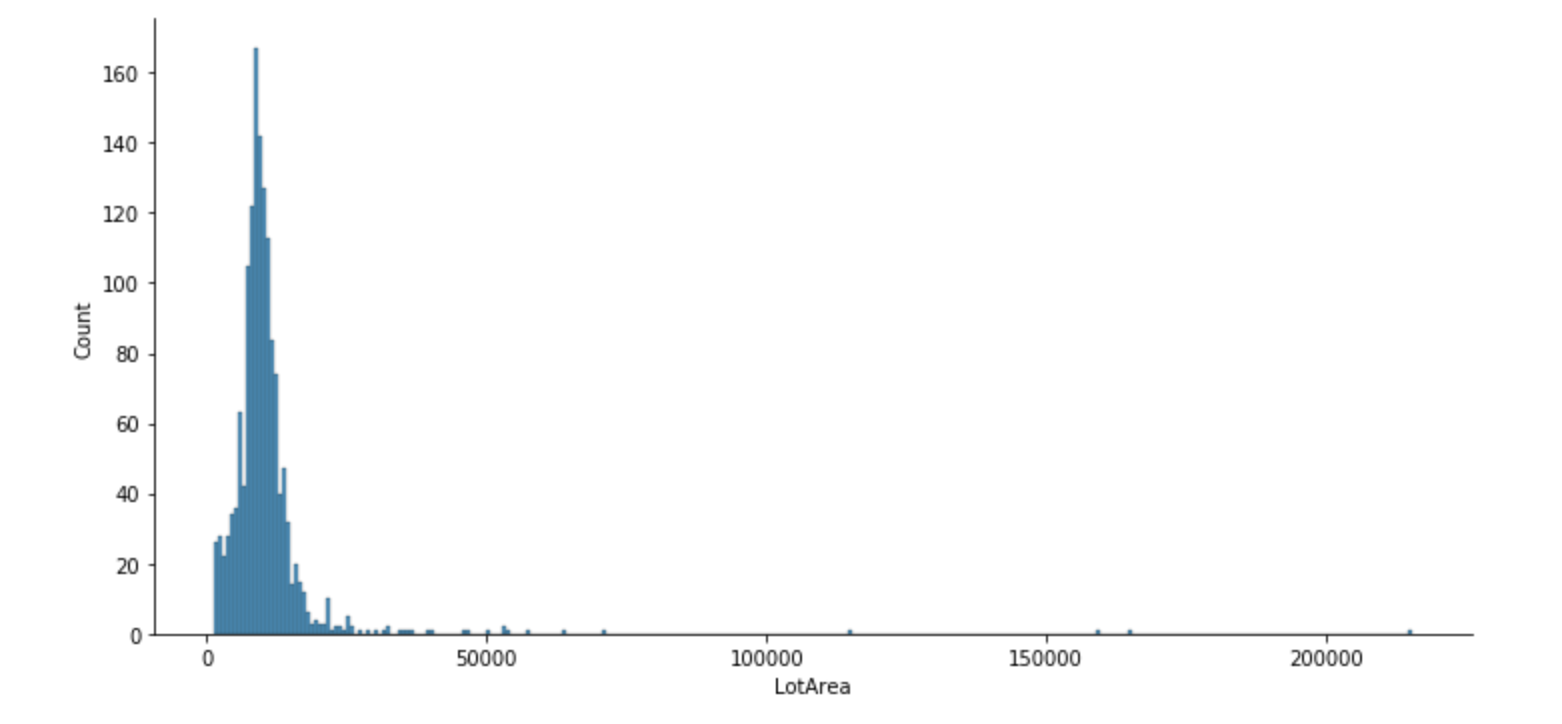
In [12]:
1 | # 可视化查看数据分布情况 |
In [13]:
1 |
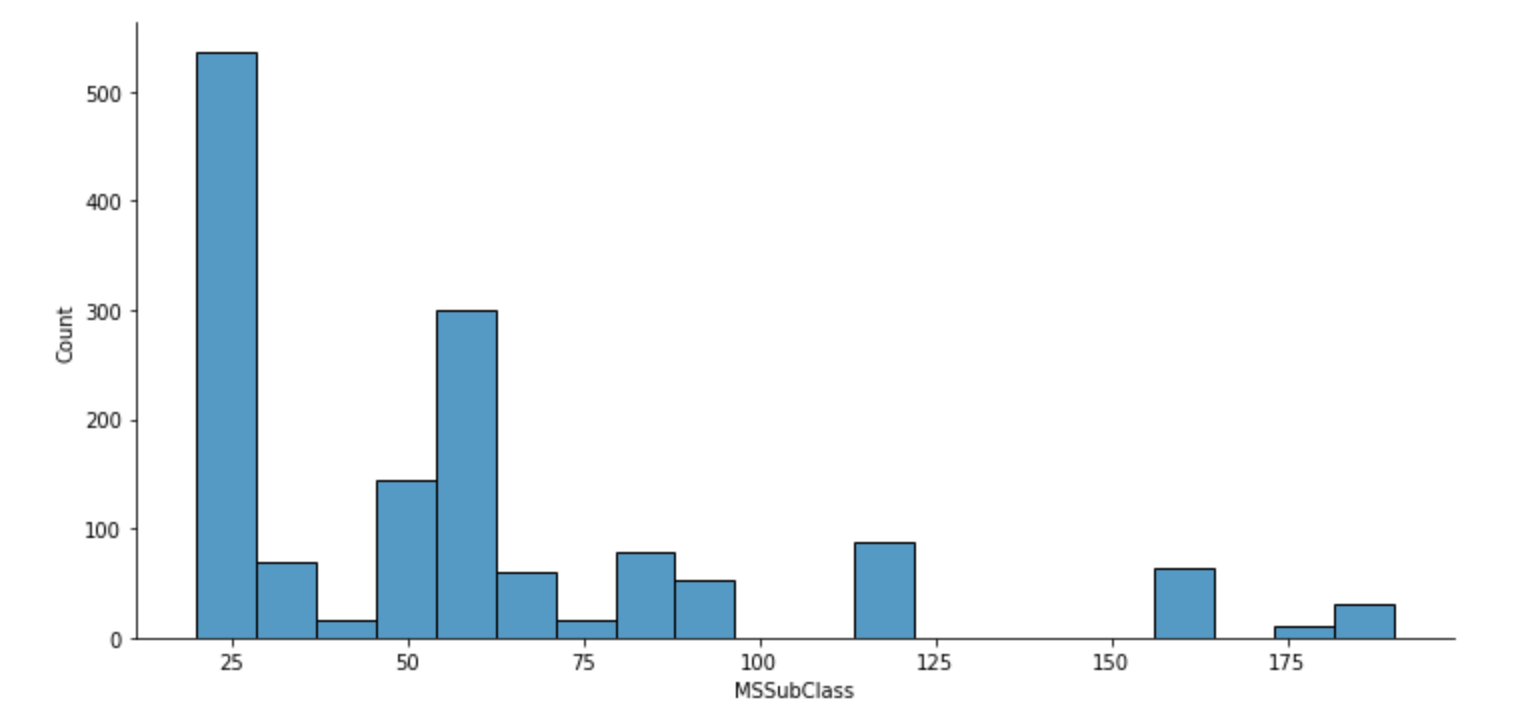
In [14]:
1 | # 可视化查看数据分布情况 |
In [15]:
1 |
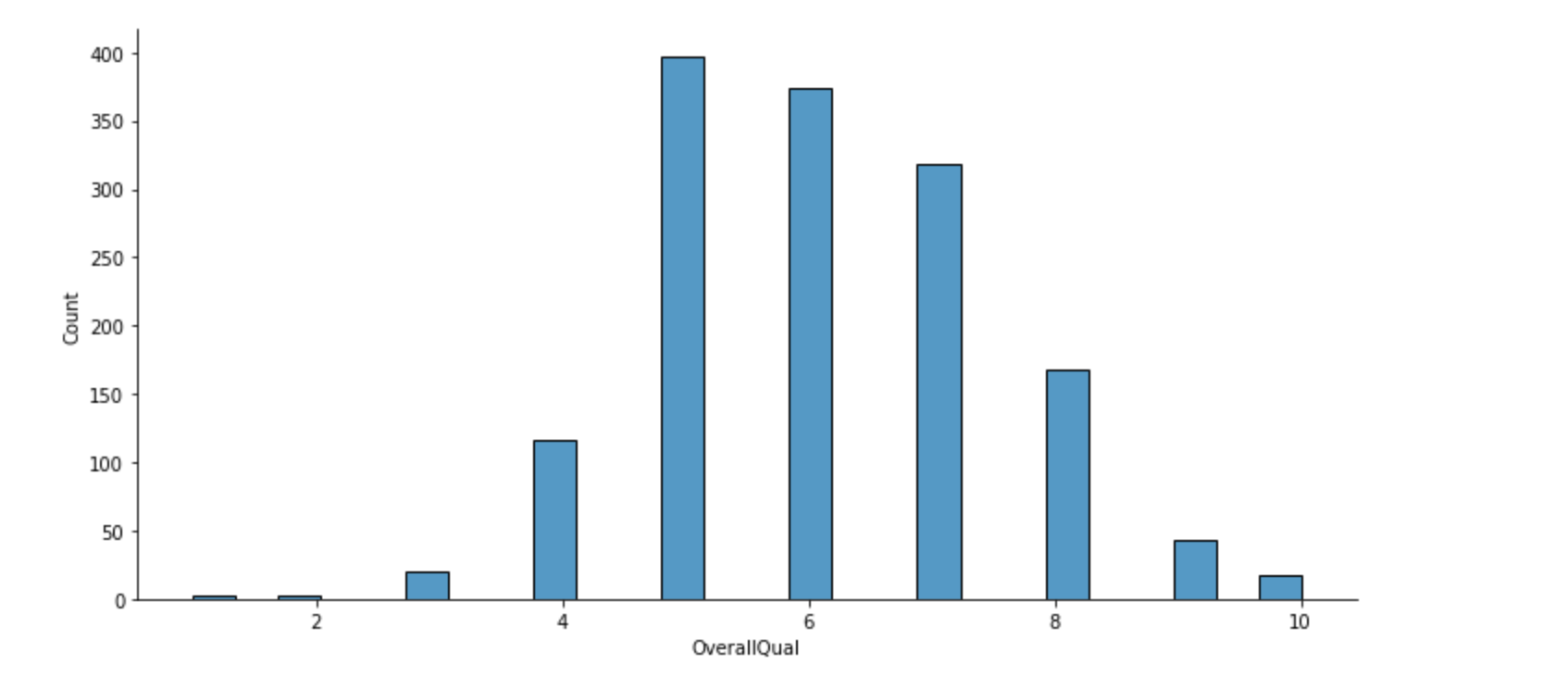
In [16]:
1 | plt.figure(figsize=(10,8)) |
In [17]:
1 | df_num = train.select_dtypes(include=["float64","int64"]) |
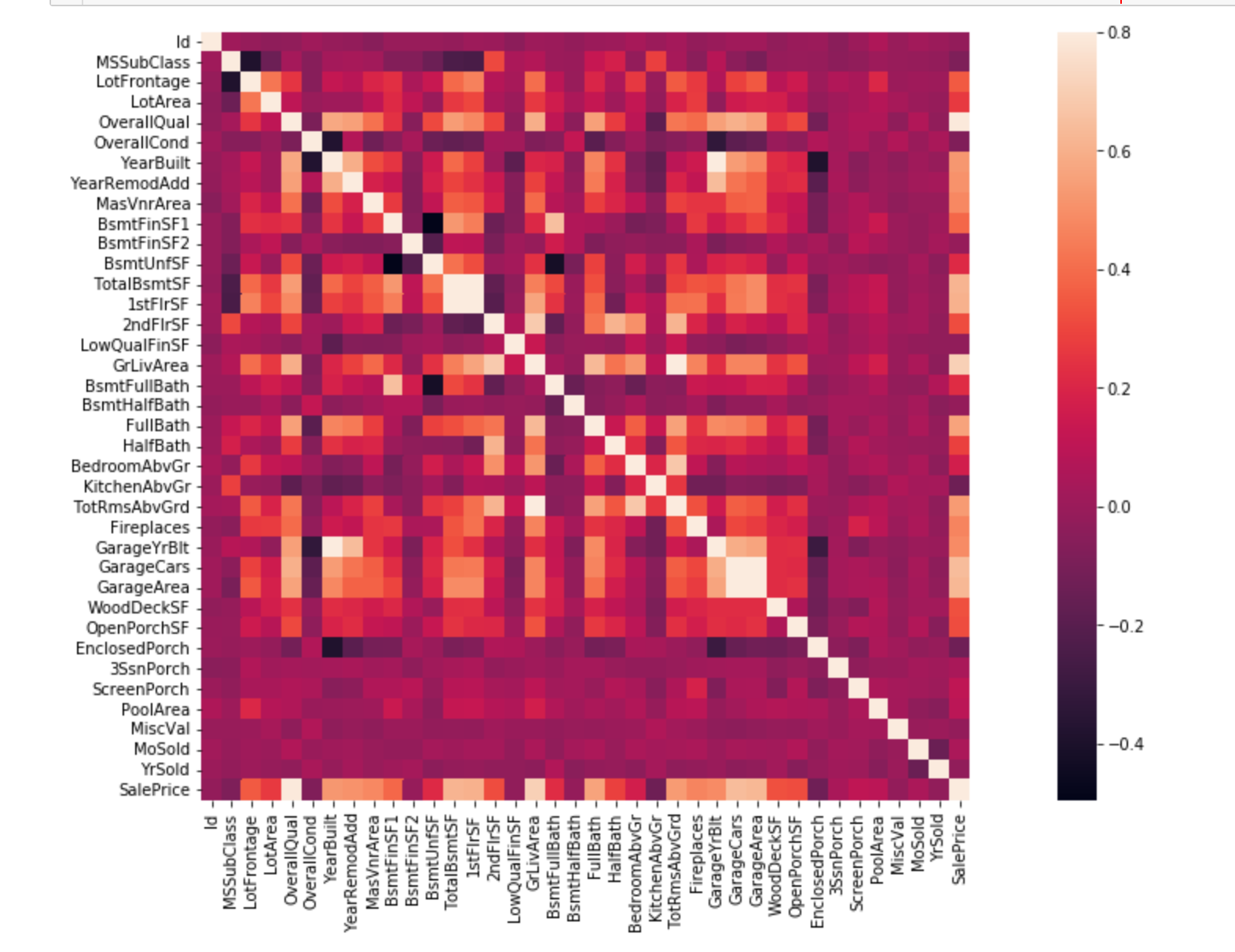
连续型变量相关性(附)
- 正相关:如果一个特征增加导致另一个特征增加,则它们正相关。值1表示完全正相关
- 负相关:如果一个特征增加导致另一个特征减少,则它们负相关。值-1表示完全正相关
如果两个特征完全正相关,这意味着两个特征包含高度相似的信息,信息中几乎没有或者完全没有差异,这就是多重线性。
所以可以尽可能删除冗余特征,降低训练时间和难度。
In [18]:
1 | corrmat = train.corr() |
类别型
- 观察类别型变量的基本分布情况:即观察每个属性的频次
- 根据频次统计信息,发现热点属性和极少出现的属性
数据字段:
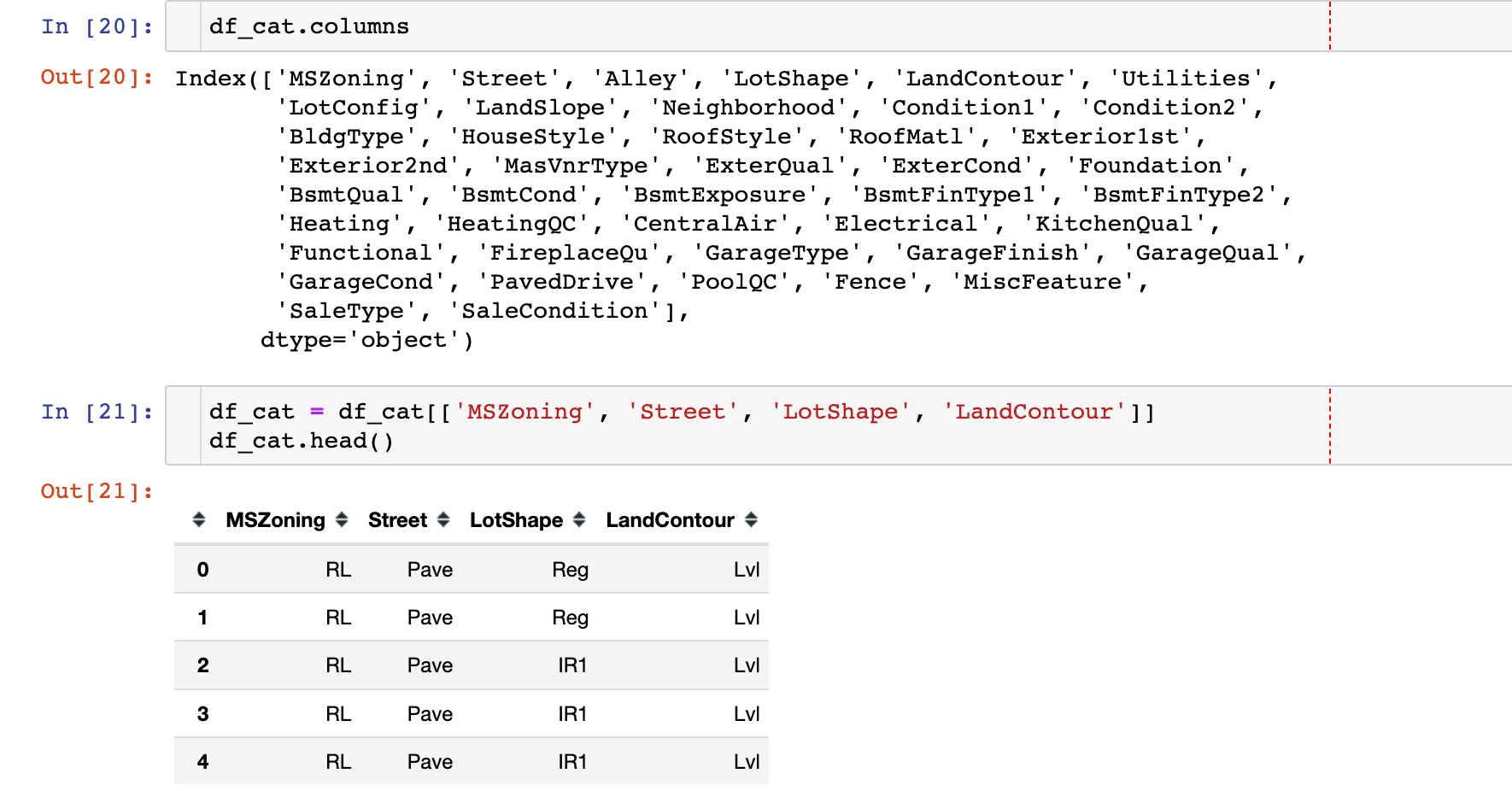
字段的基本统计量信息:
In [22]:
1 | plt.figure(figsize=(8,6)) |
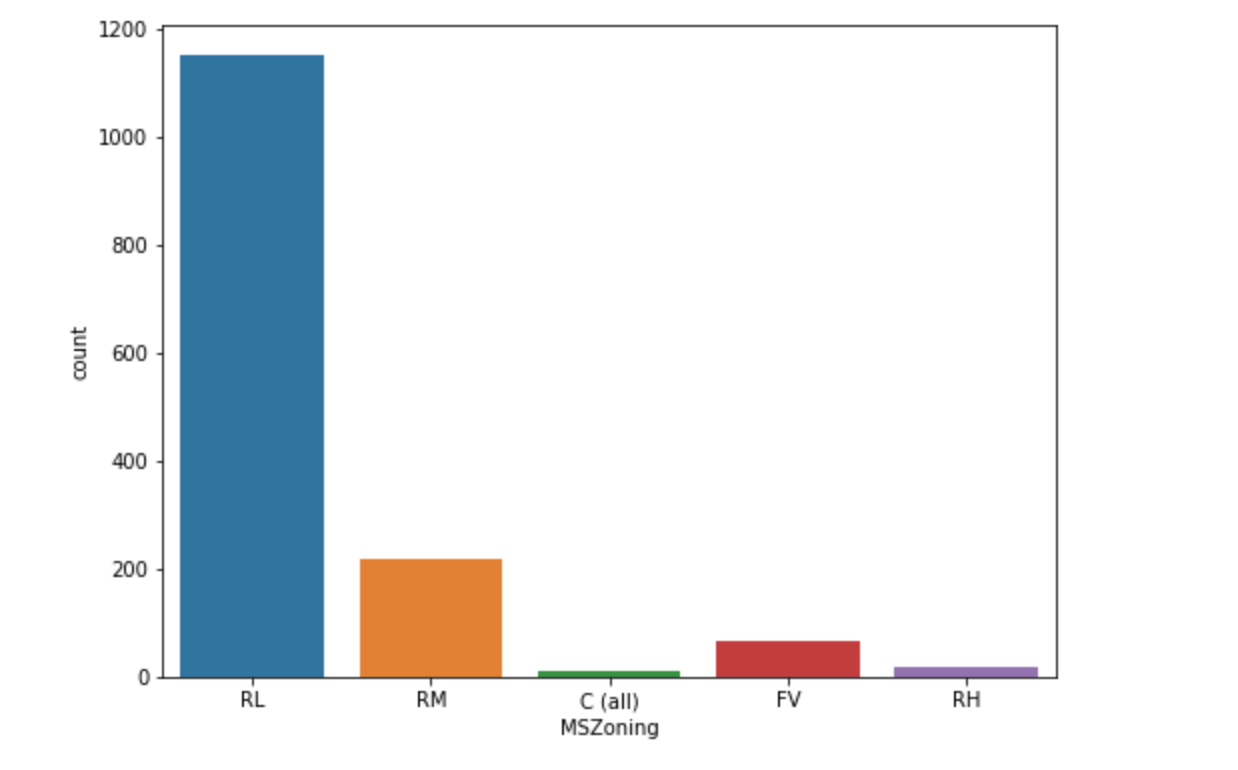
1 | plt.figure(figsize=(8,6)) |
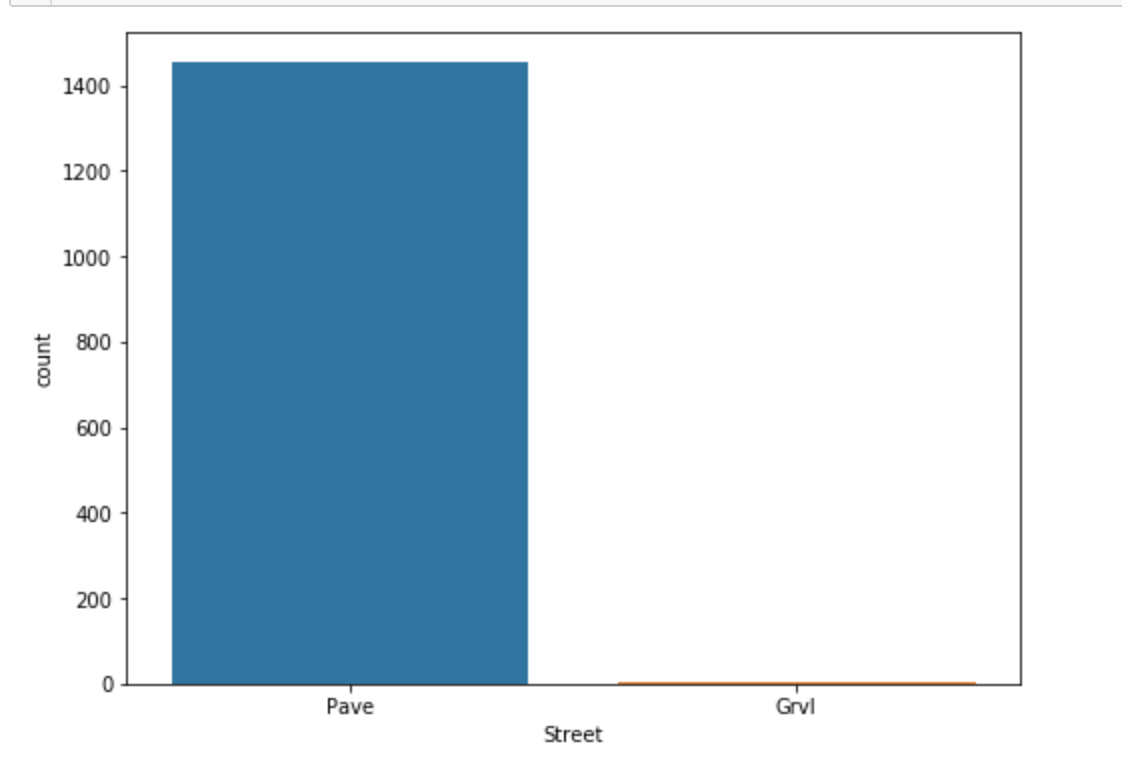
多变量分析
In [24]:
1 | plt.style.use("seaborn-white") |
Out[24]:
1 | Neighborhood OverallQual |
In [25]:
1 | type_cluster.unstack() # 部分截图 |
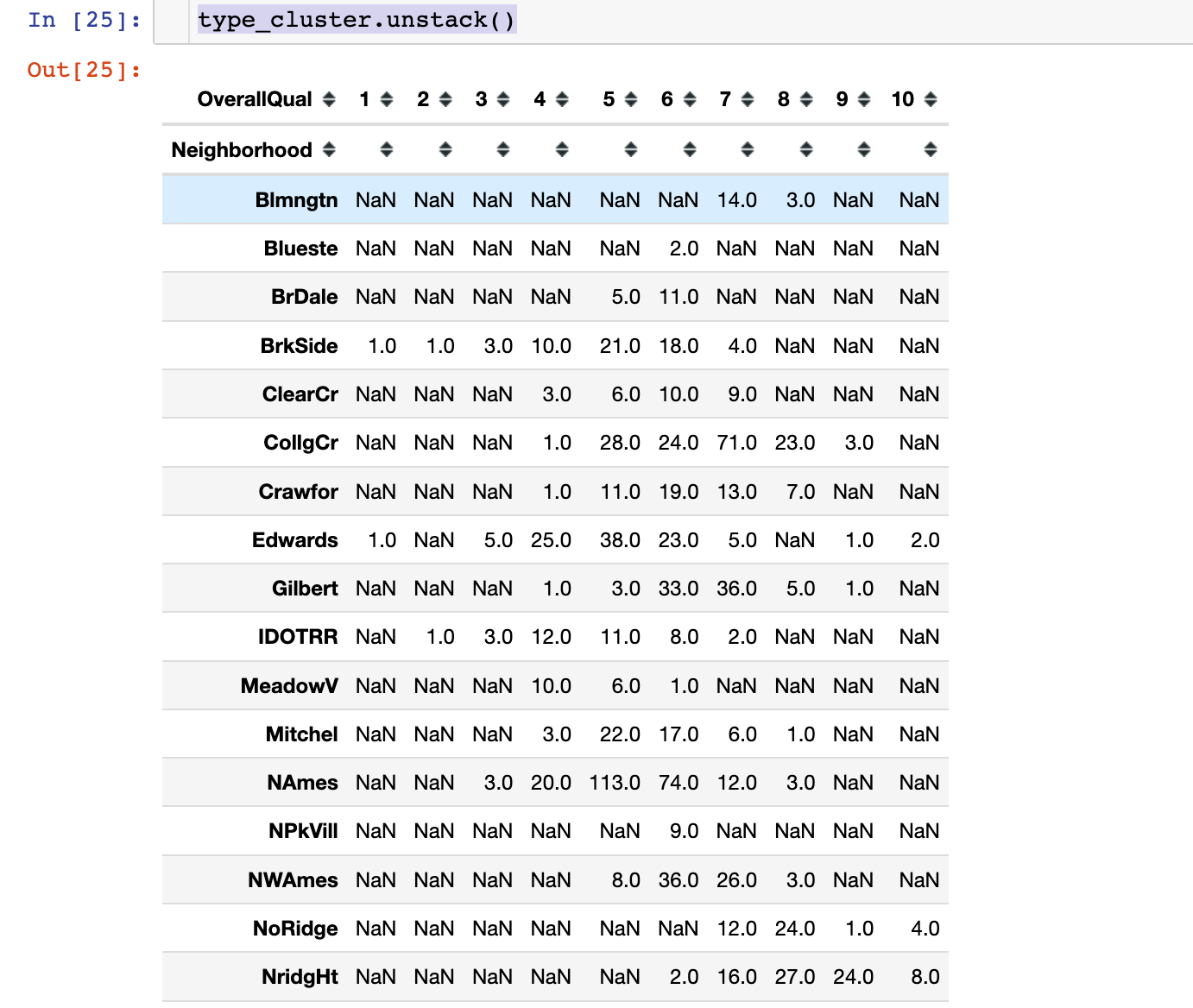
1 | # plt.figure(figsize=(20,10)) |
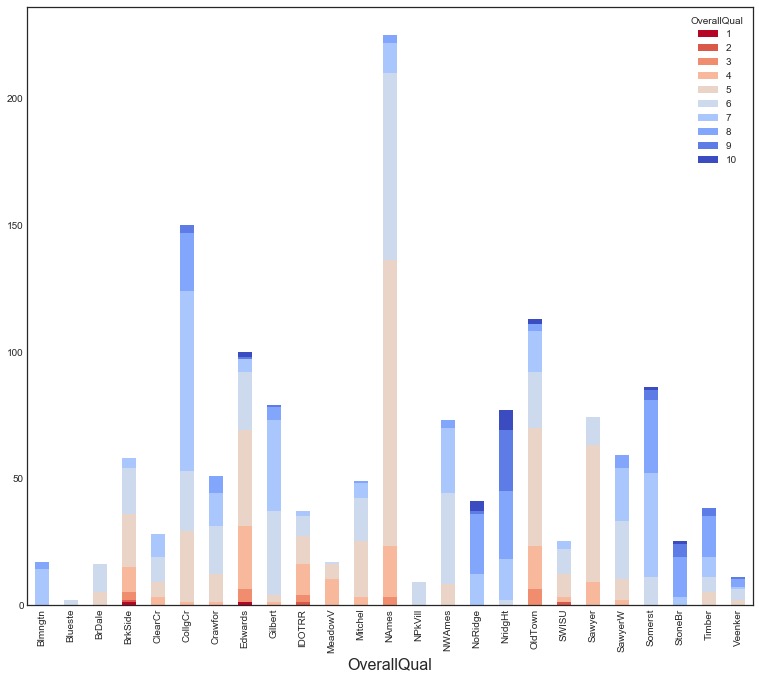
1 | plt.figure(figsize=(18,12)) |
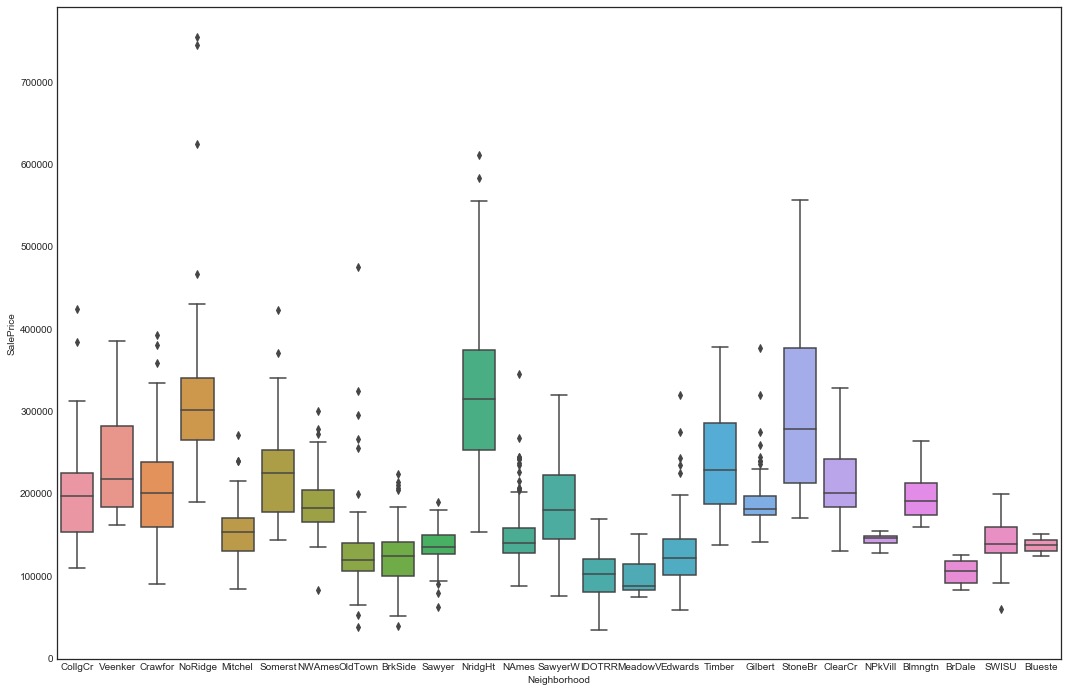
小结:上面的图形说明高评价位置(NoRidge、NrigHt和StoneBr)对应高SalePrice,也说明房屋位置评价和高房价有较强的相关性。可以构造新特征:
- 两个类别特征的交叉组合特征
- 组合特征下房屋均价
模型分析
学习曲线
学习曲线是机器学习中用来进行模型效果评估的工具,能够反映训练集和验证集在训练迭代中的分数变化情况。
欠拟合:指模型无法学习到训练集中数据所展现的信息。一般如果训练的损失曲线是一条平坦的线或者相对较高的线,这就表明该模型根本无法学习训练集。 过拟合:模型对训练集学习得很好,但是对新数据的学习效果很差,导致泛化能力差
欠拟合和过拟合曲线的对比:
特征重要性分析
通过模型训练可以得到特征重要性,比如树模型通过计算特征的信息增益或者分裂次数等得到特征的重要性,模型LR或者SVM等使用特征系数作为特征重要组成部分(特征系数越大,则表示对模型的影响越大)。
误差分析
误差分析就是我们通过模型预测的结果来发现问题的关键所在。
- 回归问题:看预测结果的分布
- 分类问题:看混淆矩阵
