
机器学习算法竞赛实战-竞赛问题建模
更新《机器学习算法竞赛实战》一书的阅读笔记,更多详细的内容请阅读原书。本文的主要内容包含:
- 竞赛问题的3个主要部分
- -如何理解竞赛问题
- 机器学习的样本选择
- 如何线下评估模型
- 实战案例

竞赛问题建模
针对具体问题的建模分为3个部分:
- 赛题理解
- 样本选择
- 线下评估策略
赛题理解
- 业务背景:深入业务、明确目标
- 数据理解:数据基础层、数据描述层;前者关注:字段来源、取数逻辑、计算逻辑、生产过程等,后者关注:数据字段的统计量,便于进行统计分析和概括描述。
- 评价指标:
- 分类模型:错误率、精度、准确率(查准率precision)、召回率(recall,查全率)、F1_score、ROC曲线、AUC和对数损失(logloss)
- 回归模型:平均绝对误差MAE、均方误差MSE、均方根误差RMSE、平均百分比误差MAPE
样本选择
主要原因
影响数据质量的4个原因:
- 数据集过大(侧重数据量)
- 存在噪声和异常值
- 样本数据冗余(侧重数据特征的冗余),一般进行特征筛选(降维)
- 正负样本不均衡:使用欠采样或者过采样来解决
准确方法
解决数据集过大或者正负样本不均衡的方法:
- 简单随机抽样:有放回和无放回
- 分层采样:评分加权处理(对不同的类别进行加权)、欠采样(随机欠采样、Tomek Links)、过采样(随机过采样、SMOTE算法)
应用常景
什么场景下需要处理样本不均衡问题?
- 对召回率有特别要求:即对正样本的预测比负样本重要,如果不处理的话,很难取得较好的建模结果。
- 如果评价指标是AUC:处理或不处理差别不大
- 如果正负样本同等重要,无需多做处理
线下评估策略
- 强时序性问题:将数据按照时间的先后顺序进行排序,选择最近时间的数据作为测试集
- 弱时序性问题:K折交叉验证
- K=2,2折交叉验证:将数据分为训练集和测试集,受数据划分方式影响大
- K=N,N折交叉验证(留一验证 leave-one-out Validation),N-1个训练集,1个测试集;训练过程计算量大
- K=5或者10,折中办法:比如K=5表示取其中4份作为训练集,1份作为验证集,循环5次,取5次训练的评价结果的均值或者投票表决
1 | # 10折交叉验证 |
实战案例
导入库
In [1]:
1 | import pandas as pd |
加载数据
In [2]:
1 | train = pd.read_csv("train.csv") |
In [3]:
1 | train.head() |
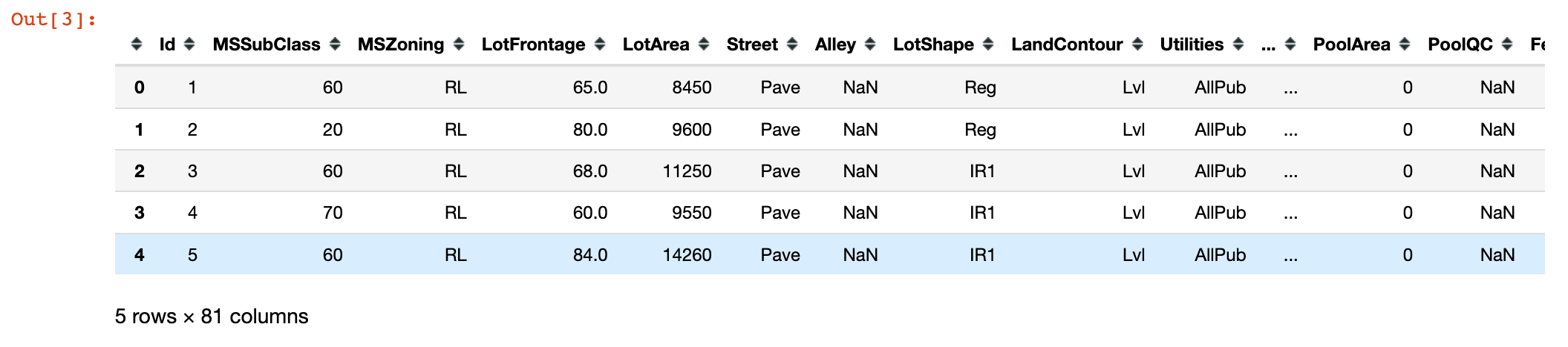
查看数据的基本信息情况:
In [4]:
1 | train.isnull().sum() |
Out[4]:
1 | Id 0 |
In [5]:
1 | train.dtypes |
Out[5]:
1 | Id int64 |
In [6]:
1 | train.describe() |
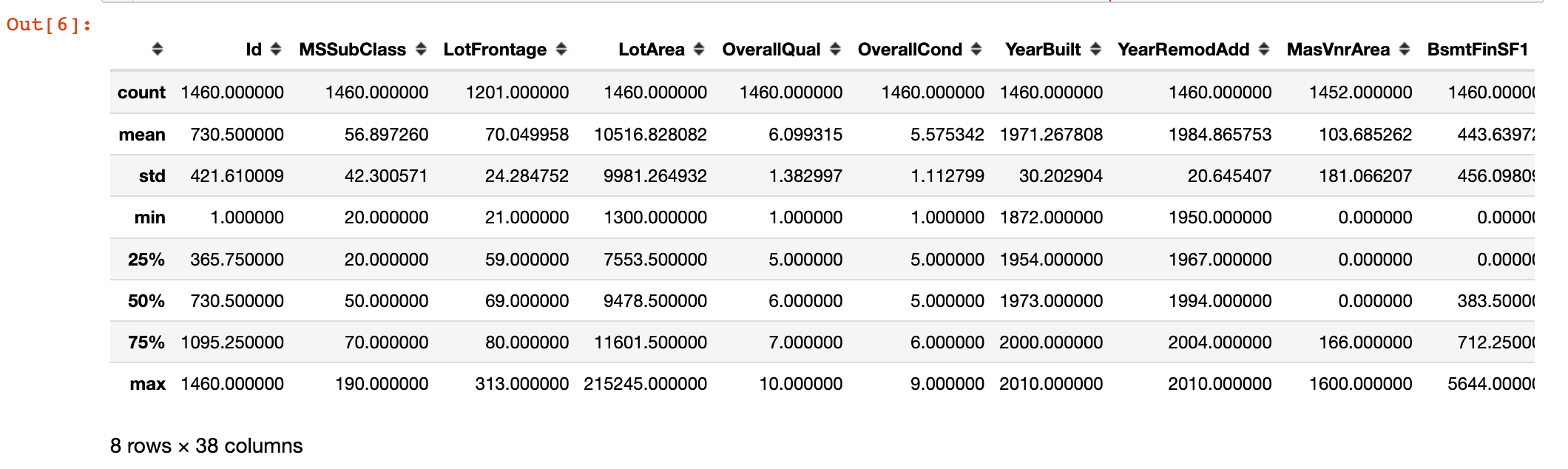
数据预处理
In [7]:
1 | all_data = pd.concat([train,test]) # 数据合并 |
In [8]:
1 | # 缺失值均值填充 |
In [9]:
1 | all_data.head() |
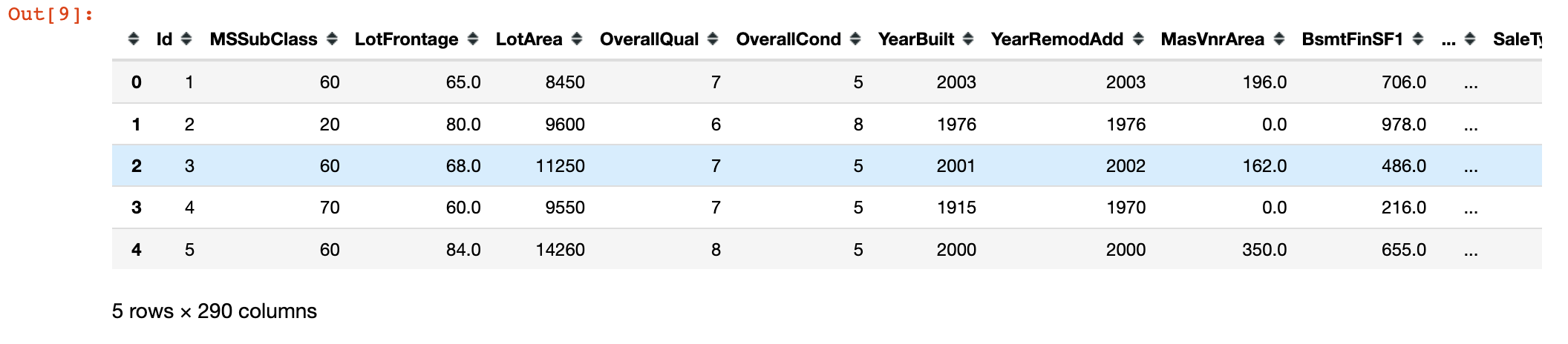
数据集划分
In [10]:
1 | X_train = all_data[:train.shape[0]] |
模型训练与评估
In [11]:
1 | from sklearn.model_selection import KFold |
