
本篇文章中主要是介绍卷积神经网络
CNN
-
神经元和神经网络
-
卷积
- 什么是卷积
- 动态卷积
- 重要概念
-
全连接网络
- 局部相关性
- 权值共享性
-
离散卷积

神经元

基本形式为wx+b,其中
-
$x_1,x_2$表示输入向量
-
$w_1,w_2$表示的是权重,几个输入对应几个权重
-
b是偏置
-
$g(z)$为激活函数
-
a是输出
神经网络

- 最左边的原始输入信息称之为输入层:众多神经元(Neuron)接受大量非线形输入讯息。输入的讯息称为输入向量
- 最右边的神经元称之为输出层:讯息在神经元链接中传输、分析、权衡,形成输出结果。输出的讯息称为输出向量
- 中间的称之为隐藏层:输入层和输出层之间众多神经元和链接组成的各个层面。如果有多个隐藏层,则意味着多个激活函数

上面神经网络的特点:
- 具有多层隐藏层
- 层与层之间是全连接的结构
- 同一层的神经元之间没有连接
卷积
- 左边是输入(7*7*3中,7*7代表图像的像素/长宽,3代表R、G、B 三个颜色通道)
- 中间部分是两个不同的滤波器Filter w0、Filter w1
- 最右边则是两个不同的输出
卷积实现
对图像(不同的窗口数据)和滤波矩阵(一组固定的权值的神经元)做內积(逐个元素相乘再相加)的操作就是卷积

举个例子:左边是原始数据,中间的是滤波器,右边是卷积结果
计算过程:4*0 + 0*0 + 0*0 + 0*0 + 0*1 + 0*1 + 0*0 + 0*1 + -4*2 = -8

如果输入是图像,不同的滤波器,得到不同的输出数据,比如颜色的深浅、轮廓灯

动态卷积
在CNN中,滤波器filter(带着一组固定权重的神经元)对局部输入数据进行卷积计算。每计算完一个数据窗口内的局部数据后,数据窗口不断平移滑动,直到计算完所有数据。几个重要参数:
- 深度depth:神经元个数,决定输出的depth厚度。同时代表滤波器个数
- 步长stride:决定滑动多少步可以到边缘
- 填充值zero-padding:在外围边缘补充若干圈0,方便从初始位置以步长为单位可以刚好滑倒末尾位置,通俗地讲就是为了总长能被步长整除。

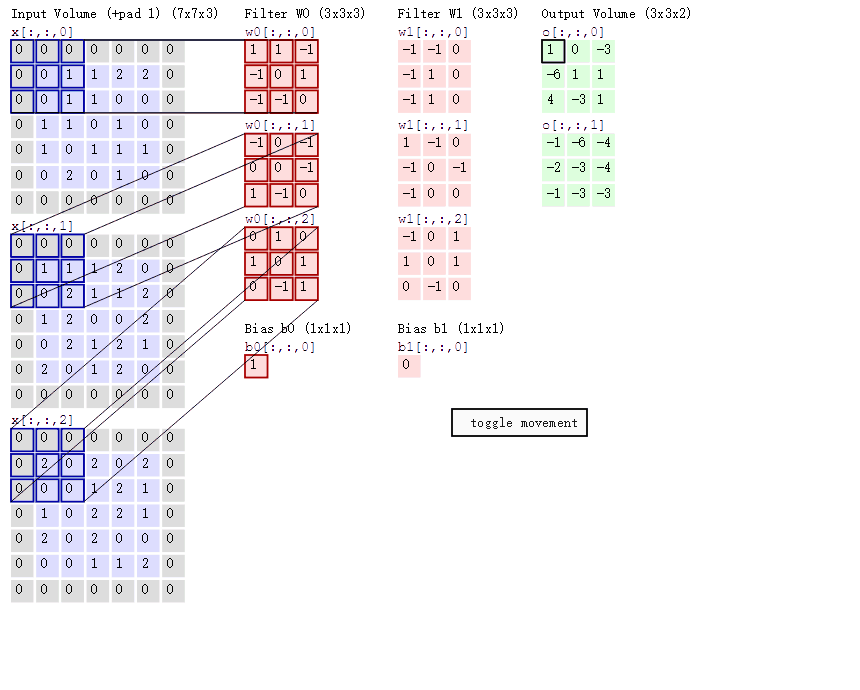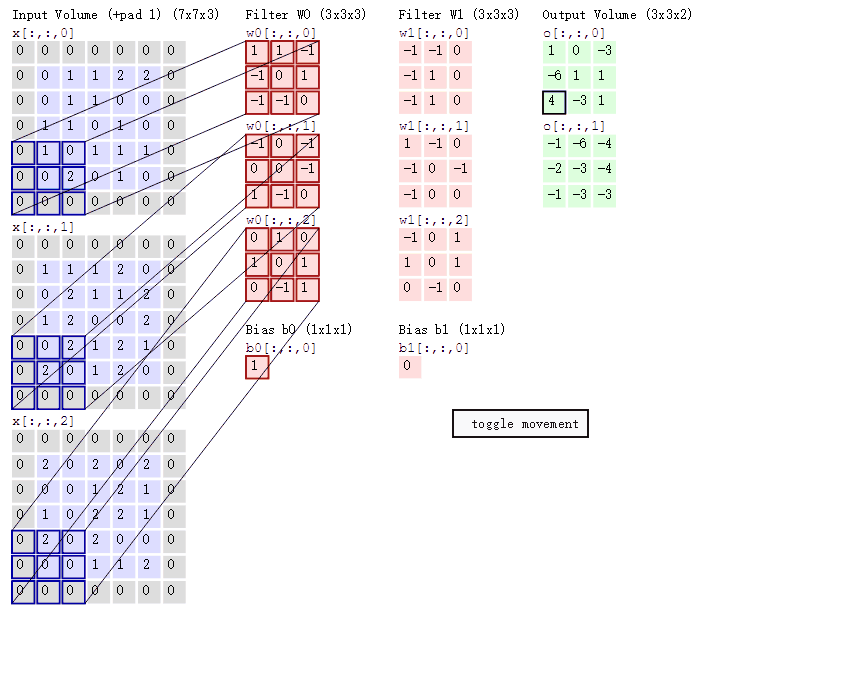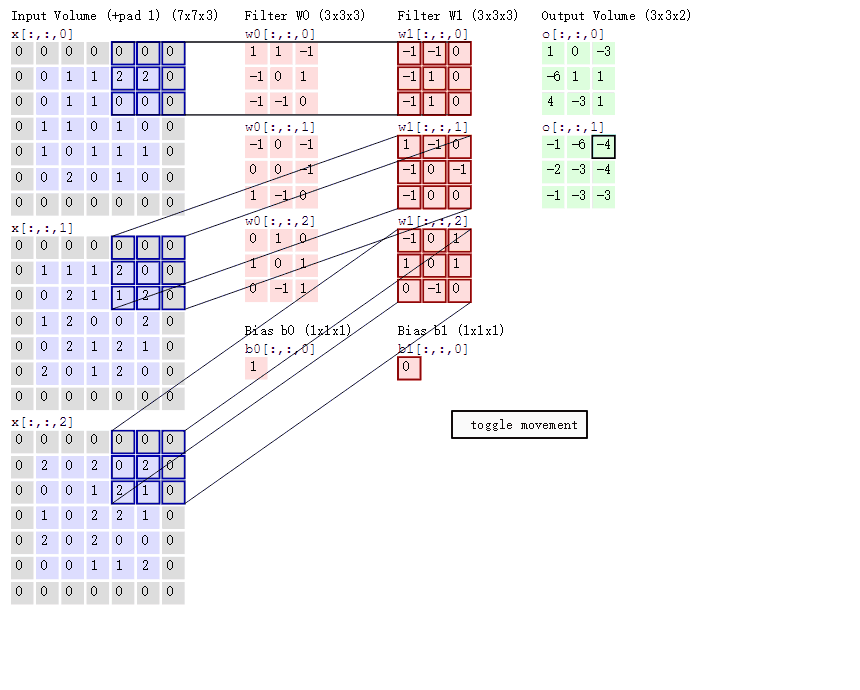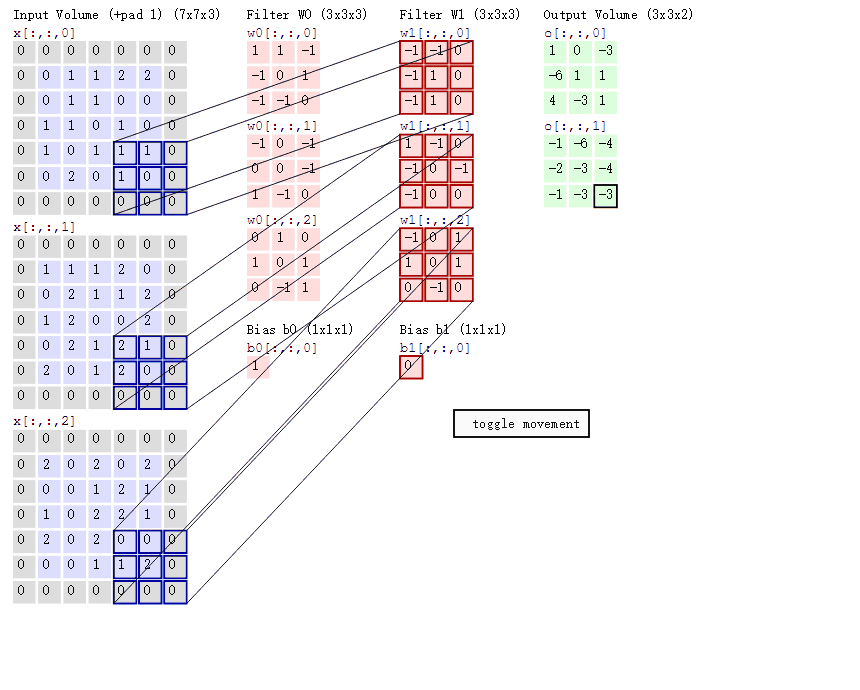
- 两个神经元,即depth=2,意味着两个滤波器
- 窗口每次移动两个步长,取$3*3$的局部数据,即stride=2
- 填充
zero_padding=1
针对上面的动态卷积图的理解:
- 左边是输入(7*7*3中,7*7代表图像的像素/长宽,3代表R、G、B 三个颜色通道)
- 中间部分是两个不同的滤波器Filter w0、Filter w1
- 最右边则是两个不同的输出
重要概念
局部感知机制:左边数据在变化,每次滤波器都是针对某一局部的数据窗口进行卷积
参数(权重)共享机制:数据窗口滑动,导致输入在变化,但中间滤波器Filter $w_0$的权重(即每个神经元连接数据窗口的权重)是固定不变的。
**相乘再相加:**通过$wx+b$实现,每个输出和权重相乘再加上偏置b

全连接网络
下面是一个4层的全连接网络
- 输入时28*28,打平后是784节点的手写数字图片
- 中间的隐藏层的节点数是256
- 输出层的节点是10

1 | import tensorflow as tf |
参数计算
假设输入节点是n,输出节点是m
- 权值张量W包含的参数量是n*m
- 偏置张量b包含的参数量是m
全连接层总的参数是n*m+m
设置TF的显存使用方式
1 | gpus = tf.config.experimental.list_physical_devices('GPU') |
这段代码表示是tf.config.experimental.set_memory_growth(gpu, True)TF按需申请显存资源
全连接网络的参数集是非常大的
局部相关性
2D数据的处理demo
-
全连接方式
- 每个像素点和输出节点相连接,提取每个输入节点的特征信息
- 稠密的连接方式造成了全连接层参数量大,计算代价高

当全连接层的激活函数$\sigma$为空是,全连接层也称之为线性层Linear Layer。
$$
o_{j}=\sigma\left(\sum_{i \in n o d e s(I)} w_{i j} x_{i}+b_{j}\right)
$$
输出节点和输入节点是否有必要全部连接在一起呢?
- 选择最重要的部分节点
- 抛弃重要性较低的部分节点
$$
o_{j}=\sigma\left(\sum_{i \in \operatorname{top}(I, j, k)} w_{i j} x_{i}+b_{j}\right)
$$
其中$𝑡𝑜𝑝(𝐼,𝑗,𝑘)$表示 $I$ 层中对于$J$层中的$𝑗$号节点重要性最高的前$𝑘$个节点集合
节点数量从$||I||||J||$减少到$k||J||$个
重要性如何判断
认为与当前像素欧式距离小于等于$\frac{k}{\sqrt{2}}$的像素点的重要性是比较高的。
感受野
以实心网格为参考,表征的是每个像素对于中心像素的重要性分布情况:
- 网格内部的重要性高
- 网格外部的重要性低
高宽为k的窗口称之为感受野

基于这样的距离方式:只考虑距离自己较近的部分节点,忽略较远的节点,权连接层变成局部连接的方式

此时输入和输出的关系式为:
$$
o_{j}=\sigma\left(\sum_{d i s t(i, j) \leq \frac{k}{\sqrt{2}}} w_{i j} x_{i}+b_{j}\right)
$$
其中$dist(i,j)$表示的是点i,j之前的欧式距离。
权值共享
通过感受野的方式将参数从全连接层的$||I||||J||$减少到了$kk*||J||$。通过权值共享的方式,每层使用相同的权值矩阵W,网络层的参数量总是$k*k$。k的取值一般是比较小的。

通过上面的权值共享矩阵W和感受野内部的像素相乘累加,得到了左上角像素的输出值

通过局部连接,权值共享的网络方式其实就是卷积神经网络。
离散卷积
在信号处理领域,使用的比较多的是离散卷积运算
-
卷:翻转平移
-
积:积分运算
比如$g(x)$经过翻转变成$g(-x)$再平移变成$g(k-x)$
离散卷积的累加运算
$$
(f * g)(n)=\sum_{\tau=-\infty}^{\infty} f(\tau) g(n-\tau)
$$
2D离散卷积
函数的图片是$f(m,n)$,2D卷积核是$g(m,n)$;两个函数在有效区内有值,其余是0
$$
[f * g](m, n)=\sum_{i=-\infty}^{\infty} \sum_{j=-\infty}^{\infty} f(i, j) g(m-i, n-j)
$$
卷积核$g(i,j)$通过翻转变成了$g(-i,-j)$;比如$(m,n)=(-1,-1)$,$g(-1-i,-1-j)$表示的卷积核向左、向上各平移一个单位长度。
$$
\begin{aligned}
{[f*g]}(-1,-1) &=\sum_{i=-\infty}^{\infty} \sum_{j=-\infty}^{\infty} f(i, j) g(-1-i,-1-j) \
&=\sum_{i \in[-1,1]} \sum_{j \in[-1,1]} f(i, j) g(-1-i,-1-j)
\end{aligned}
$$
看一个栗子:
图片函数f和卷积核函数g

2D函数只在$i\in[-1,1]$和$j\in[-1,1]$的时候存在值,其他位置是0,计算${f*g}$
- 0表示横纵不动
- -1表示纵轴向上移动一个单位


2D离散卷积核运算流程:每次通过移动卷积核窗口函数与图片对应位置处的像素进行累加,得到位置的输出值。
-
卷积核即是窗口为k大小的权值矩阵W
-
大小为k的窗口的感受野与权值矩阵相乘累加,得到此位置的输出值
-
通过权值共享,移动卷积核,提取每个位置上的像素特征,从左上到右下,完成卷积运算

卷积神经网络
单通道输入,单卷积核
单通道输入$c_{in}=1$,单个卷积核$c_{out}=1$;输入时$55$的矩阵,卷积核是$33$
- 对应位置上的元素相乘再相加
- 计算顺序:从左到右,从上到下

- 感受野已经移动至输入 X 的有效像素的最右边,无法向右边继续移动(在不填充 无效元素的情况下)
- 感受野窗口向下移动一个步长单位(𝑠 = 1),并回到当前行的行首位置
- 继续选中新的感受野元素区域,与卷积核运算得到输出-1。

多通道输入,单卷积核
一个卷积核只能得到一个输出矩 阵,无论输入X的通道数量。需要注意的情况是
- 卷积核的通道数必须和输入X的通道数量进行匹配
- 卷积核的第i个通道和X的第i个通道进行计算,得到第i个中间矩阵
- 上面的步骤看做是单通道和单卷积核的计算过程,再把中间矩阵对应元素依次相加,作为最终输出



多通道输入,多卷积核
- 当出现多个卷积核,第i的卷积核与输入X运算之后得到第i个输出矩阵
- 全部的输出矩阵在通道维度上进行拼接stack操作,创建输出通道数的新维度

- 3通道输入,2个卷积层
- 卷积核具有相同的大小k,步长s,填充设定等值
步长
感受野密度是通过移动步长Strides来确定的。步长就是感受野每次移动的长度单位。

- 步长小:感受野以较小的幅度移动窗口,有利于提取更多的信息,输出张量的尺寸更大
- 步长大:感受野以较大幅度移动窗口,有利于减少计算代价,过滤冗余信息,输出张量的尺寸也更小。
填充padding
经过卷积运算后的输出O的高宽一般会小于输入X的高宽,有时希望输出O的高宽能够与输入X的高宽相同,从而方便网络参数的设计,残差连接等。
为了让输出O的高宽能够与输入X的相等,一般通过在原输入X的高和宽维度上面进行填充(Padding)若干无效元素操作,得到增大的输入X′。


卷积神经层的输出尺寸$[b,h^,w^,c_{out}]$由卷积核的数量$𝑐_{𝑜𝑢𝑡}$,卷积核的大小 k,步长 s, 填充数 p(只考虑上下填充数量ph相同,左右填充数量pw相同的情况)以及输入X的高宽 h/w 共同决定
$$
\mathrm{h}^{\prime}=\left|\frac{\mathrm{h}+2 * \mathrm{p}_{\mathrm{h}}-\mathrm{k}}{\mathrm{s}}\right|+1
$$
$$
\mathrm{w}^{\prime}=\left|\frac{\mathrm{w}+2 * \mathrm{p}_{\mathrm{w}}-\mathrm{k}}{\mathrm{s}}\right|+1
$$
- $p_h,p_w$表示的是高和宽的填充数量
- ||向下取整函数
卷积层实现
自定义权值
通过tf.nn.conv2d函数实现2D卷积运算
- 输入$X:[b,h,w,c_{in}]$
- 卷积核$W:[k,k,c_{in},c_{out}]$
- 输出:$O[b,h^
,w^,c_{out}]$
1 | x = tf.random.normal([2,5,5,3]) # 模拟输入,3通道,高宽是5 |
卷积层类
通过卷积层类layers.Conv2D不需要手动定义卷积核W和偏置张量b,直接调用类实例即可完成卷积层的前向计算。
在新建卷积层类时,只需要指定卷积核数量filters,卷积核大小kernal_size,步长strides,填充padding
1 | # 1. 创建卷积层类 |
LeNet-5实战
创建卷积层
1 | from tensorflow.keras import Sequential |
训练阶段
1 | from tensorflow.keras import losses, optimizers # 误差计算,优化器模块 |
CNN层级结构
层级结构图

-
最左边是数据输入层:对数据进行去均值(各个维度都中心化为0,避免数据过多偏差,影响训练效果)、归一化、PCA/白化等
-
中间层:
- CONV:卷积计算层,线性乘积求和
- RELU:激励层
- POOL:池化层,取出区域平均或者最大值

-
最右边:FC,全连接层
CNN在进行图片识别的过程中是将位置图片的局部和标准的图案的局部进行一个个的对比,这个对比计算的过程便是卷积操作。如果图片出现变形,如何处理?引入了features
正常情况下:

稍微变形:

特征features
对于CNN来说,它是一块一块地来进行比对。它拿来比对的这个“小块”我们称之为Features(特征)
在两幅图中大致相同的位置找到一些粗糙的特征进行匹配,CNN能够更好的看到两幅图的相似性,相比起传统的整幅图逐一比对的方法。
每一个feature就像是一个小图(就是一个比较小的有值的二维数组)。不同的Feature匹配图像中不同的特征。如果特征能够匹配上,则两幅图就是相似的。

每个features很有可能就是任何含有字母X的四个角和它的中心。其中一个角和中心


具体过程

